Not That Easy for Computers
Hazards - 매 사이클마다 한 개의 명령어를 못하게 하는 장애요소
Structural hazards - HW 컨포넌트를 서로 쓰려하는 충돌상황 -> 제한된 HW 리소스
Data hazards - 현재 진행하는 명령어가 이전에 수행한 결과에 의존하는 문제
Control hazards - branch 명령어와 다른 명령어 섞으면 발생함(롤백문제)
Common Solution
파이프라인의 이러한 문제가 없을 때 까지 기달리는 것(stall)이 일반 해결책, 이를 위해 0을 흘려보내는데 이를 버블(bubble)이라함
One Memory Port/Structural Hazards
메모리가 한 개 밖에 없는데 둘이 읽으려구 함 -> Structural hazards 발생
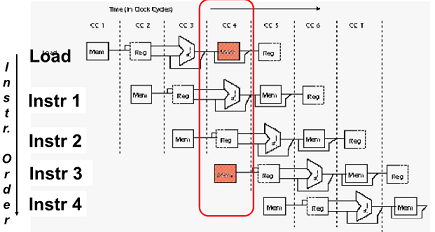
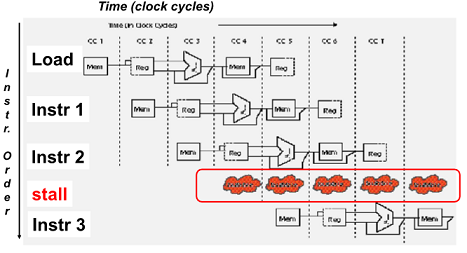
가장 simple 한 방법은 stall
Speed Up Equation for Pipelining
실제 퍼포먼스에 어떤 영향을 미치는지 파악하는 법
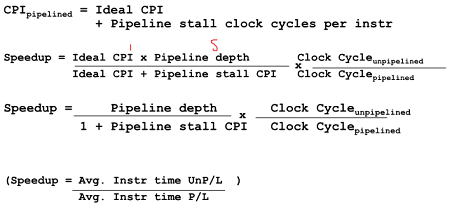
CPI - pipelined 구동패턴에 있어 한 개의 명령어마다 평균 몇 개의 cycle 이 소요되었는지 계산
CPI = Ideal한 값은 1임 + Hazard에 의해 발생하는 추가 cycles 수로 정의
Example: Dual-port vs Single-port

Data Hazard on R1
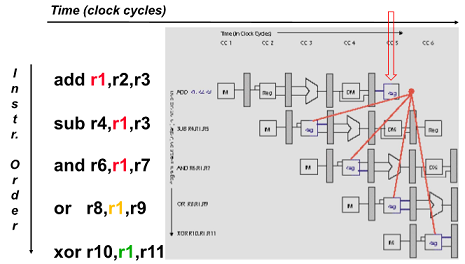
cc5에서 r1에 데이터를 쓰는데
뒤에 instruction들이 r1을 쓰기 전에 읽으려함
-> 이거 읽어버리면 이전의 r1 데이터를 읽어 오동작함
유일하게 xor 만 제대로 동작함
위의 Hazrad를 simple 하게 stall 하기 위해 어떤 것들이 필요한지?
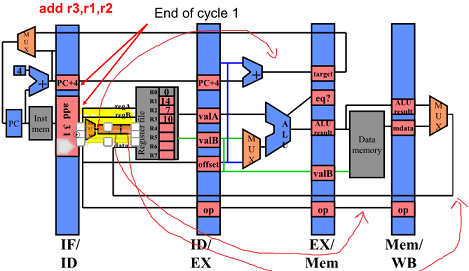
End of Cycle 1
Stall 하기위해 data hazard detect 하고 제어하기 위한 logic 설치
End of Cycle 2
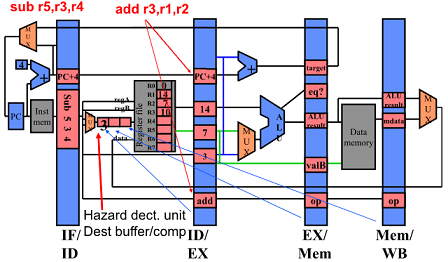
Hazard dect. unit은 Dest register를 적는 부분에 존재
쓰고자 하는 register의 number 를 씀(3)
First Half of Cycle 3
add 명령어는 다음으로 가는데 sub는 Hazard detection 함
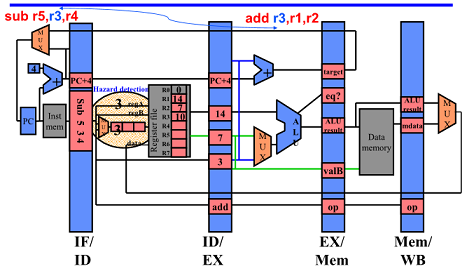
regA 의 3과 Dest unit의 3 이 같으므로 detection 판단하여 stall 시킴
End of Cycle 3
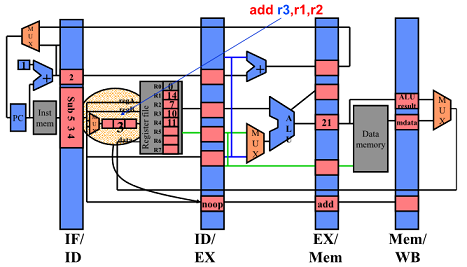
First Half of Cycle 4
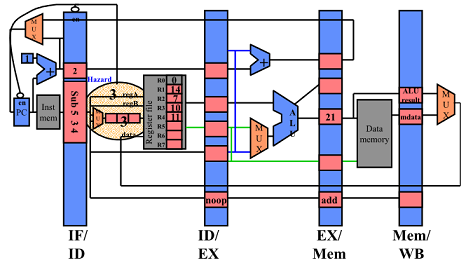
End of Cycle 4
cycle 4에서도 한번더 hazard dection 됨
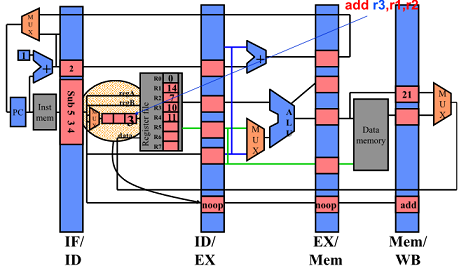
First Half of Cycle 5
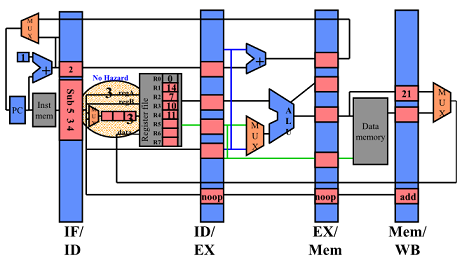
Hazard 발생안함
End of Cycle 5
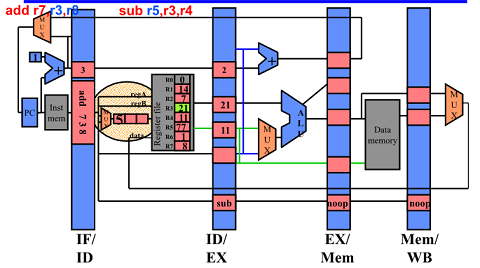
Three Generic Data Hazards
Read After Write(RAW)
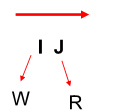
I명령어가 Write 하기전에 뒤 따라오는 J 명령어가 Read 하려는 경우
Write After Read(WAR)
I명령어가 읽으려고 하기전에 뒤 따라오는 J가 Write 하는 경우
DLX에서는 일어나지 않음
Write After Write(WAW)
I명령어가 Write 하기전에 뒤 따라오는 J가 먼저 Write 하는 경우
DLX에서는 일어나지 않음
Forwarding to Avoid Data Hazard
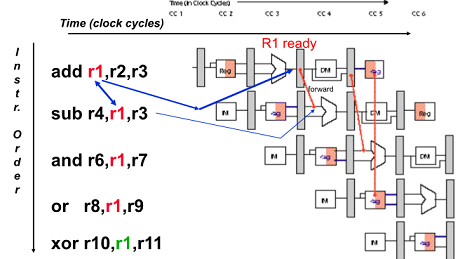
R1은 cc3에 준비됨, 쓰여지는 시간이 cc5임
Wire만 있으면 준비된 값 필요할 때 전달(Forwarding)
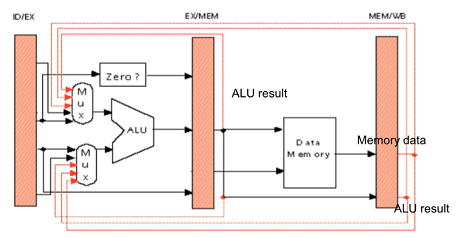
Wire로 제공해 Mux를 이용해 합당한 입력 선택만 해주면 됨
Data Hazard Even with Forwarding
load 명령어는 memory로 부터 데이터를 읽었을 때 준비됨
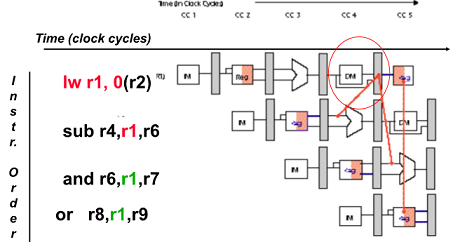
Forward 만 해서는 안됨
Stall 해주어야함!(한 cycle bubble 허용)
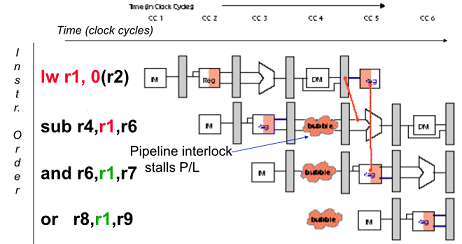
Pipleline interlock 을 시킴
Software Scheduling to Avoid Load Hazards
컴파일러에게 해주도록 하는 것이 스케줄링
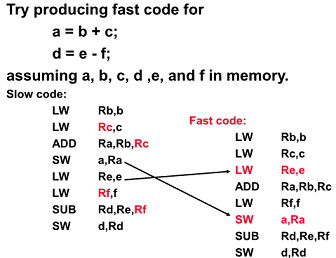
코드 재배치를 통해 squence 에도 문제 없이 해결
Control Hazard on Branches Three Stage Stall
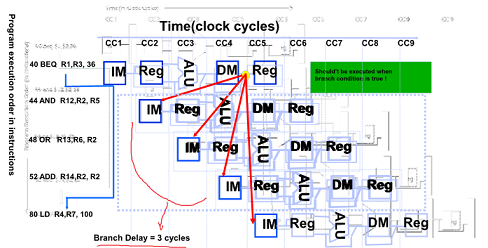
뒤에 들어왔던 3 cycles 의 instruction이 무효화 됨
Branch Stall Impact
프로그램에서 평균 20 ~ 30퍼가 branch 명령어임
30%가 branch 명렁어라 가정하면
최대 3사이클의 stall이 발생하고 CPI 를 계산하면 1+ 0.3 * 3 = 1.9 이므로 두배로 늘어남
성능저하에 매우 중요한 요인이기 때문에 그냥 놔두면 안됨
DLX
1. Jump 여부를 빨리 결정
2. Jump를 미리 계산
DLX는 =0인지아닌지만 check해서 빨리 detection 가능
Zero test를 ID/RF에 이동시키고 Add 하나 더 써서 미리 계산하면 3사이클 낭비를 1사이클로 줄일 수 있음
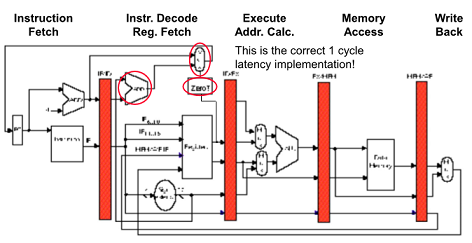
1cycle 무조건 발생하는 것 줄이는 방법이 없을까?
Four Branch Hazard Alternatives
- Stall until branch direction is clear
- Predict Branch Not Taken(Branch 안할 꺼라고 생각하고 진행, 47%가 branch 안하므로)
- Predict Branch Taken (Branch 할꺼라고 생각하고 진행하지만 DLX에서는 target address를 계산할 수 없어 1cycle 무조건 발생)
- Delayed Branch(Branch 명령 전에 다른 instruction을 하나 더 실행 시키고 Branch Taken)
Delayed Branch
어떤 instruction을 delay slot에 채울지?
보통 Branch 전의 명령어를 넣어줌
다른 방안들도 존재(branch taken이면 branch 이후 명령어를 넣어주는 등)
Compiler의 도움을 활용해서 single branch delay slot을 사용하면 대략 60% 정도 채울 수 있고 그중 80% 가 유용해 대략 50% 정도가 제대로 쓸 수 있음
이를 통해 Penality를 0.5로 줄일 수 있음