Advanced Pipelining and Instrction Level Parallelism(ILP)
Loop 가 ILP를 활용하기위한 가장 쉬운 대상
-> 이를 활용하는 것 Loop unrolling, vector instructions
FP Loop
LD와 ADDD 간의 F0때문에 1사이클 stall 이 야기되는 것 가정
ADDD 다음 SD 의 RAW 가 발생하므로 2사이클 stall이 발생
delayed branch slot을 활용하도록 DLX를 설계했기 때문에 NOP를 해서 아무것도 채워넣지 않아 또 1사이클 stall 발생

그래서 총 9사이클이 delay 됨
Revised FP Loop Minimizing Stalls
SD를 NOP에 채우고 2stall hide 시킴

6사이클로 줄임
LD, ADD, SD는 유요한 work (지금은 1:1로 구성됨)
유용한 work를 더 많이 수행하게 하는 방법 : Loop Unroll
Unroll Loop Four Times
Loop를 유효한 일을 4배 증가시켜 한번 돌 때 4번 수행시키도록 펼침

레지스트 이름을 바꾸어 서로 다른 loop body로 구성
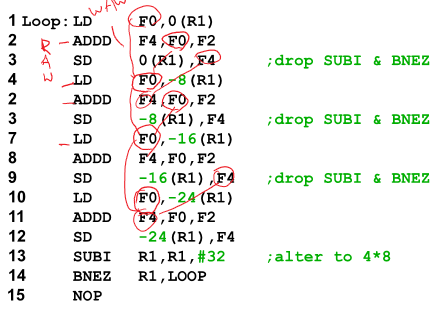
Unrolled Loop That Minimizes Stalls
코드 rearrage 까지 시키면 LD 끼리, ADDD 끼리 모아 놓아 명령어간의 latency 제거

있는 그래도 총 14사이클이 소요됨
SD, LD 이동시킬 때 컴파일러가 뺀 만큼 더해주니까 이동가능
Compiler Perspectives on Code Movement: Dependencies vs Hazards
Compiler 적인 측면에서 code 이동을 어떤 관점에서 하는지?
컴파일러가 보는 것은 dependencies, 하드웨어 명령어들에서 발생하는 문제는 Hazards
컴파일러는 프로그램 내의 dependencies 에 관심을 가지고 스케줄링 수행
- data dependencies : RAW 와 똑같은 개념 (i 번째 명령어가 j에게 데이터를 제공하게 되면 j 가 i의 수행결과를 활용하는 경우을 의미) -> 컴파일러는 i, j를 병렬로 사용할 수 없음을 알 수 있음
Where are the data dependencies?
Data 의존성 - 뒤쫒아가는 명령어가 이전 명령어의 결과를 활용하는 경우 Dependencies가 존재한다고 설명함
레지스터 F4에대해 data dependencies가 존재한다(RAW 와 비슷한 컨셉)

name dependence
두개의 명령어가 레지스터 나 메모리 위치의 같은 이름을 사용할 때 conflict 남
- Antidependence(WAR 해저드와 같은 개념)
- Output dependence(WAW 해저드와 같은 개념)
이 관계를 끊어 버리기 위한 방법?
Name 이 충돌하는 것이기 때문에 이름을 변경하면 해결됨 레지스터 rename
Removing name dependencies
Register를 더 많이 사용해서 충돌이 발생하지 않게함

메모리 content 인 경우 runtime에 detection되기 때문에 파악하기 어려움
Control dependence
브랜치 명령어와 다른 명령어 혼합 사용때 발생함
Code movement 시킬 때, 병렬화 시킬 때 검토하는 척도
Branch 명령어 이전을 branch 뒤로 옮긴다거나 반대로 하면 안되는 기준으로 사용
When Safe to Unroll Loop for ILP?
for (i=1; i<=100; i=i+1) { A[i+1] = A[i] + C[i]; B[i+1] = B[i] + A[i+1]; }
이전 수행 결과를 뒤에 사용이 되고(A[i+1]), loop를 돌 때 이전의 iteration 결과를 다음 iteration에서 사용하여 iteration간 상호 dependence 가 존재(loop-carried dependence)하는 경우 병렬로 수행 고려대상이 아님 -> loop unroll 할 수 없음
HW Schemes: Instruction Parallelism(1/2)
Data Hazard는 Dynamic schedule 기법을 통해 극복
현재까지는 static 스캐쥴링이였고, 이를 극복히가 위해 dynamic하게 명령어를 스케줄링하는 방법을 검토
왜 하드웨어로 run time에 검토하려고 하는가?
컴파일 타임에 파악할 수 없는 의존성을 파악할 수 있음
한 머신에 작성된 code가 다른 머신에서 잘 작동하고, 컴파일러가 간단해즈므로
어떤 stall이 발생하면 그 다음 진행하지 못하는 것이 큰 문제 Divd 와 add 명령어 사이에 F0에 대한 RAW harzard 가 존재
뒤의 subd는 위와 관계 없는데 똑같이 기달리는 문제가 발생
이런 경우 나머지와 subd는 관계 없이 subd를 구동시키는 방안이 있으면 좋음
SUBD를 먼저 수행시킬 수 있는 것 - out of order execution
DLX를 out of order 로 재 설계하려고함
기존의 ID를 두 개로 나누어 설계
이런 구조 이름을 Scoreboard라하고 현재 많은 프로세서에 활용(risc)
HW Schemes: Instruction Parallelism(2/2)
ID를 Issue와 Read 로 나눔
ID를 Issue에서는 structural hazard가 있는지 없는지 보고 read에서는 RAW가 있는지 없는 지 봄
위의 조건 1, 2 가 충족되면 명령어 수행하는 구조로 설계
Out-of-order execution 머신이라함
충분한 리소스와 data dependency가 없을 때 가능한데, 목표는 명령어 수행을 빨리 시키기 위함임
Scoreboard Implications
Out-of-order를 지원하려면 WAR, WAW 도 검토해야함
WAR 처리방안
Read한다음 write해야함
Queue에 둘다 넣고 읽을 때는 read operands stage에서만 읽도록 함
WAW는 detect 한 다음 이전 명령어가 끝날 때 까지 그냥 stall함
Four Stages of Scoreboard Control
Issue: WAW 나 구조적 harard를 발견하고 발견되면 stall 아니면 Issue
Read operands: RAW 체크, data hazard가 없어질 때까지 stall
Execution: Operend 두개가 다 있으니까 그냥 수행하면됨
Write result: WAR hazard 체크
Write하려했는데 이전에 수행하는 명령어가 아직 읽어갔는지 안읽어 갔는지 체크하고 안 읽어 갔으면 stall하고 아니면 그냥 write 하면됨
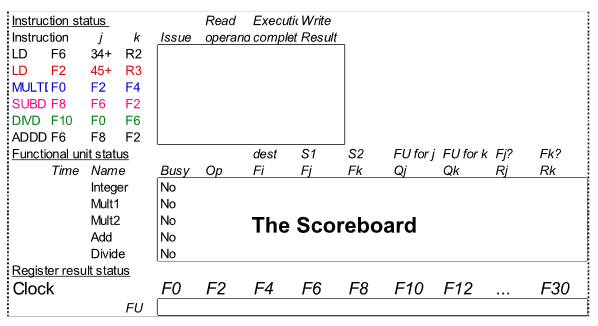
Three Parts of the Scoreboard
Instruction status - 4steps중 어디인지 보여줌
Functional unit status

Register result status
Scoreboard Example
Scoreboard Limitation
Forwarding 기술사용 못함
Instructions 사이즈 양이 작은공간에 맞추어져 있음
Functional unit 도 몇 개 안되어 빈번한 구조적 해저드 발생 구조적 해저드 발생하면 그냥 stall
WAR, WAW도 그냥 stall