Branch Prediction
Branch 가 파이프라인 stall의 큰 영향을 미쳐 handling 필요
점프할 것인지 아닌지 예측해서 파이프라인 stall을 감소시킬려고함
Cpu 수행시간의 중요 영향을 미침
Dynamic Branch Prediction
Performance = 예측의 정확도와 mispredictino을 했을 때의 cost 함수로서 정의함
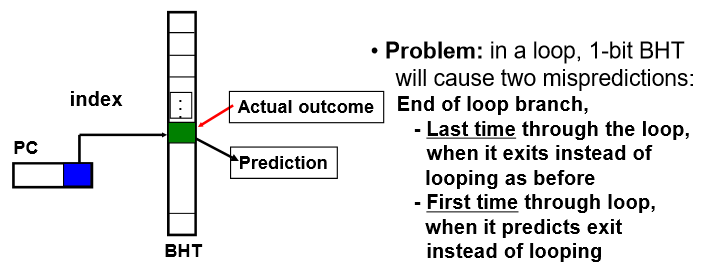
가장 simple한 branch predictino 방법은 1-bit BHT(Branch History Table)
address 하위 몇 bit를 테이블 indexing 을 위해 사용하고 해당 index에 가면 1bit 의 information에 전에 jump 여부가 있음
이전 branch 가 taken 했는지 안했는지 보여줌
1-Bit Branch History Table
dynamic 하게 prediction 하는 가장 간단한 방법
branch 명령어가 프로그램에서 대부분 이전에 했던 그대로 돌아가는 locality가 있기 때문에 활용할 수 있음
PC의 하위 몇 bit 추출해서 index로 사용해 1이면 jump 함 0이면 안함하고 BHT에 적어줌
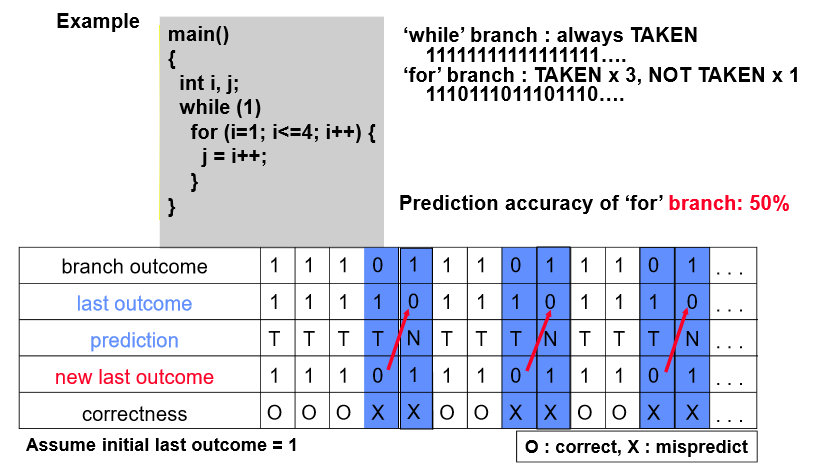
Example
Prediction Path를 과거의 값 하나만 가지고 바꾸기 때문에 Prediction를 delay를 주어서 바꾸면 어떨까? -> 2 bit Branch Prediction
2-Bit Branch History Table
Prediction을 delay 해서 바꾸기
Misprediction을 연속적으로 2번 얻을 때 방향을 바꿈(2bit를 써서)
앞에 bit가 1이면 taken 0이면 not taken
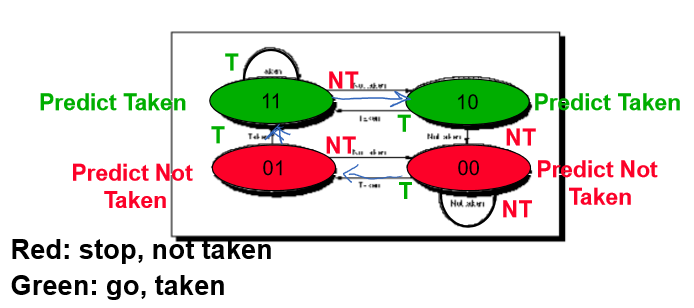
Example
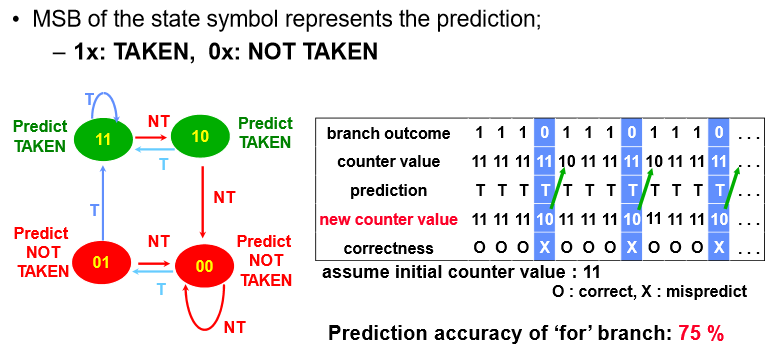
accuracy가 75%로 상승됨
BHT Accuracy
Branch history table accuracy
왜 misprediction을 얻게되는가?
1. 예측을 잘못
2. Index 를 하는데 index 값이 그 놈이 아닐 수 있음
-> 32bit address 중 하위 몇 비트만 이용하기 때문에 반드시 그것이라고 볼 수 없음
테스트해보니 4096만 있어도 무한대의 테이블을 운영하는 것과 같은 성능을 냄(82~99% 까지 성능을 보임)
성능증대를 위해
- 버퍼 사이즈를 증가해 hit ratio 높이던지
- Prediction 방법을 좀 더 정확하게
Correlating Branches
최근에 발생한 브랜치는 관계가 있다
Idea - 최근에 발생하는 m개의 branch에 대해 taken 인지 not taken인지 기록했다가 이를 근거로 다음에 수행해야하는 예측을 수행
(m, n)
m: 최근 branch 명령어
m=2면 2^2 4개의 table 선택(00, 01, 10, 11) - n=2 2bit
주어진 인덱스에 대해 이전에 수행된 두개의 결과에 따라 table을 결정
2bit Branch History Table 은 (0, 2) 로 표현됨(최근에 발생한 branch 명령어 안씀)
Correlating Branches Example(1/2)
d= 2, 0, 2, 0 … 이라고 가정
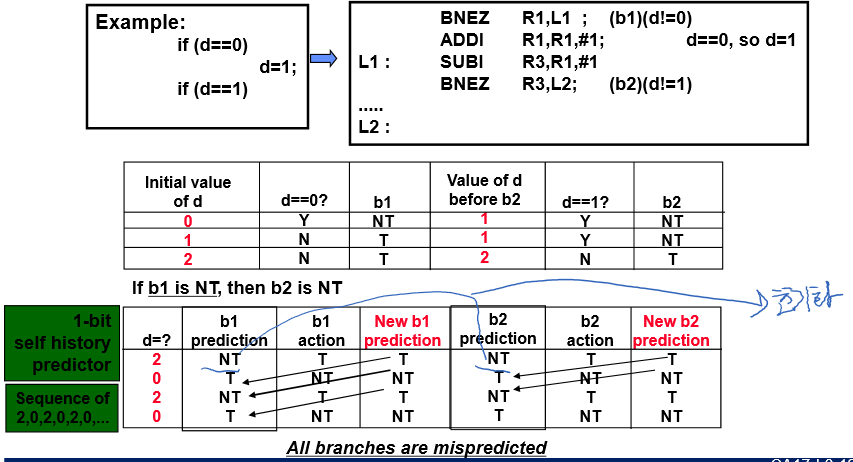
Branch 상관관계 고려 안한 1-bit BHT 를 사용하면 모두 예측 실패할 수 있음
Correlating Branches Example(2/2)
왼쪽/오른쪽
-> 특정한 index의 정보를 두가지 운영(왼쪽 / 오른쪽) 두개 운영
바로 전의 branch명령어가 not taken이면 왼쪽을 이용하고 바로 전의 branch 명령어가 taken이면 오른쪽 정보를 이용
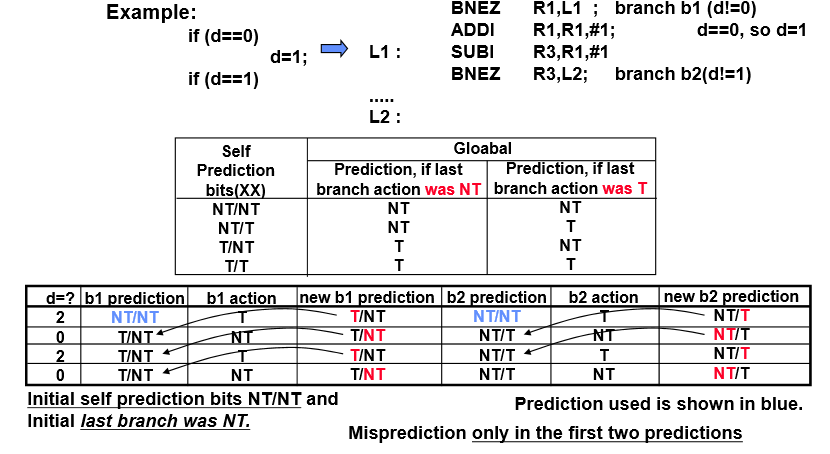
앞에 두번만 예측이 틀리고 뒤에는 다 맞음
Tournamnet Predictor
local와 global predictors를 결합해서 사용하는 것
Need Address at Same Time as Prediction
점프하려는데 이미 3개의 명령어가 들어와있는 상태임
jump하는데 확 바꾸기 그러니, 예측을 햇는데 예측과 동시에 사이클이 채워지기 전에 해당하는 target address 로 미리 가버리는게 BTB(Branch Target Buffer)
PC의 하위로 index하고 상위를 통해 tag 확인 하고 Predicted PC를 저장함
(tag, Predicted PC, T/NT(as predicted) 필드로 구성됨
Predicted PC로 미리가서 fetch를 함(predicted 가 T이면)
HW support for More ILP
speculative execution: branch의 결과를 미리 예측해서 예측대로 프로그램이 수행되게끔 구동하는 것
branch의 결과를 최종적으로 얻기전에 어디로 갈꺼야 하는 path를 파이프라인 시켜서 실행하는 것임
명령어가 결과를 얻기 전에 수행할 수 있는 방법임
Speculative인지 진짜 수행 결과인지 나누어서 생각
최종적으로 수행결과를 쓰지 않고 잠시 유지 시키는 것이 reorder buffer
결판이 났을 때 수행결과를 write 하는 것을 instruction commit 이라함
명령어가 commit 들을 하게 되면 register 에 업데이트 되어짐
결판이 났는데 틀렸으면 reorder buffer 에 지워버리는데 이를 undo 라함
Four Steps of Speculative Tomasulo Alogorithm
3단계에서 4단계로 변경됨
Commit 단계를 마지막에 두어 reorder buffer를 가지고 reigster 를 업데이트함
Getting CPI < 1: Issuing Multiple Instructions/Cycle
여전히 ILP (명령어단위의 병렬성을 어떻게 증대할까)
CPI가 < 1 목표
-> 한 사이클에 여러 개의 명령어 구동하는 방법
1. Superscalar - 사이클마다 여러 개의 명령어를 issue 시킴(1~8개 명령어를 한판에 수행)
2. (V)LIW(Very Long Instruction Words) - 명령어 템플릿이 기존에 명령어 한게가 많이 포함
한 개의 명령어가 이전의 단위 명령어 여러 개를 구성하는 구조
(4~16개의 명령어가 large 명령어에 다 packing 될 수 있도록 돌림)
SS는 dynamic 하게 issue하고 VLIW는 static issue를 하는 것이 차이이고 VLIW 는 compiler 가 중요함(instr를 큰 것으로 packing 해야함)
Superscalar DLX: 2 instructions, 1 FP & 1 anything else
2개가 하나의 pair로 들어감(앞에꺼가 issued 가능해야함)
Load가 1사이클 stall해야하는데 3개의 instructions 에 해당하는 delay로 확장됨
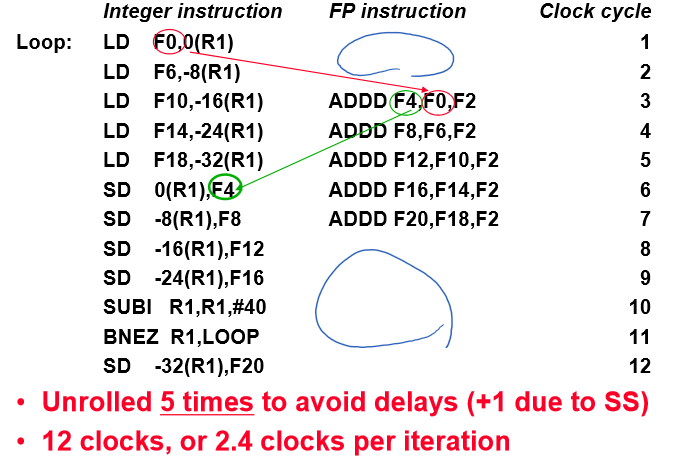
Unrolled Loop that Minimizes Stalls for Scalar
14 사이클이므로 14/4 로 3.5 per iteration

코드 재배치로 여기까지 옴
Loop Unrolling in Superscalar
코드 재배치와 Superscalar 까지 결합하면 이 정도 효과 있음
단 way가 증가할수록 빈공간이 많아짐(2, 4, 8way)
Multiple Issue Challenges
Interger/FP를 분리하는 HW일 경우
절반은 FP 연산이고 hazards가 없을 때에 최고로 얻을 수 있는게 0.5 CPI임
더 줄이려고 하면 Decode issue stage 의 설계 복잡도가 높아짐
2개의 opcode읽어서 6개 레지스터 살피고 판단하는게 복잡도가 엄청증가
Superscalar 한계에 도달
VLIW
- 컴파일러가 다해주어 편함
- 많은 연산을 한 개의 명령어에 packing 해서 돌림
예를 들어 2개의 interger ops, 2 FP ops, 2 Memory refs, 1 brach를 하나의 명령어로 표현(packing)
Loop Unrolling in VLIW

Trace Scheduling
프로그래밍이 주어지면 어디로 갈지 예측 or profiling 해서 갈 곳을 뽑아 내는 것을 trace 라함
수행 trace를 컴파일러가 선택을 하고(trace selection)
Trace에 대해 명령어를 묶어서 VLIW명령어로 squeeze 해서 만드는 단계를 trace compaction이라함
틀리면 어디로 가게끔하는 bookkeeping code 필요
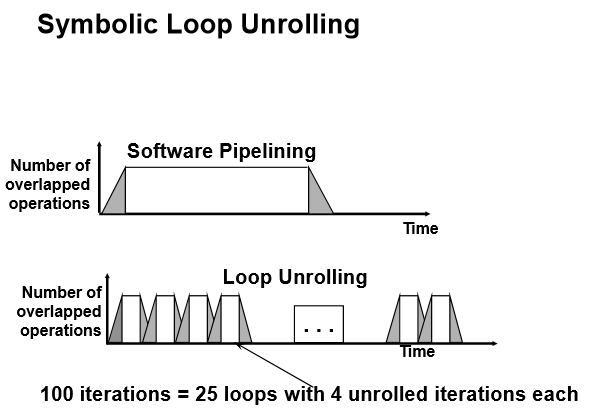
Software Pipelining
수행속도를 소프트웨어 적으로 높일 수 있는 것
Loop iteration들이 독립적으로 수행할 수 있다면 루프 재구성하면 소프트웨어적으로 파이프라인 되는 효과를 얻음
iteration 으로 부터 해당 어떤 명령어들을 추출해 루프를 재구성하면 소프트웨어 적으로 파이파라인 구동하는 형태로 바꾸어 명령어간 latency를 제거할 수 있음
루프를 각각의 다른 iteration으로 부터 추출해 명령어 재구성하는 것을 Tomasulo in SW 라 함
Example
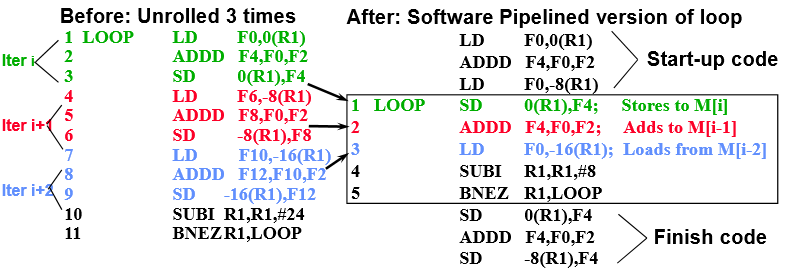
3개의 iteration 을 검토
첫번째에서는 마지막, 2번째에서는 2번째 3번째에서는 첫번째꺼를 뽑아서 재구성함
재구성된 Loop는 바로전에 ADD 수해오된 결과를 저장
바로전단에 load 한 것을 add
LD는 다음에 수행할 것을 로드
이전 iteration의 결과를 다음 iteration에 사용하게 끔해서 latency를 제거함