Why More About Memory Hierarchy?
프로세서와 메모리간 성능격차 때문에~ CPU가 자기 속도로 돌아가지 못함 메모리로 부터 명령어 fetch를 못해옴
Processor-Memory Performance Gap Trend

Alpha는 전체 CPU에서 37%정도 캐쉬가 면적차지하고 Transistors는 77%
CPU Power 소모 대부분은 캐쉬에서 발생
캐쉬는 자체적으로는 가치를 제공하는 구조가 아님
Performance gap을 맞추기 위한 overhead이지만 비용이 굉장히 커 잘 디자인해야함
Improving Cache Performance
Miss를 줄이던지 miss penalty를 줄이던지 해야함
- Reduce the miss rate
- Reduce the miss penalty
- Reduce the time to hit in the cache
Reducing Misses
Compulsory
cold start misses
캐쉬가 처음 가동될 때 아무 것도 없는 상황에서 miss가 발생하는 경우
캐쉬가 다 채워질 때 까지 발생하는 miss
(Misses in even an Infinite Cache)
capacity
공간이 작아서 나갔다가 다시 돌아오는 miss
(Misses in Fully Associative Size X Cache)
conflict
특정 index의 제한된 공간에서 나갔다 다시 들어오는 miss
collision misses, interference misses 라고도 함
Associate로 인해 발생하는 miss
Misses in N-Way Associate, size X Cache)
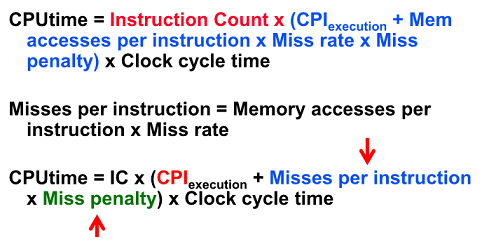
2:1 Cache Rule
miss rate 1-way associative cache size X = miss rate 2-way associative caches size X/2
size는 반으로 줄고 associative를 2배로 늘리면 miss rate는 이전과 같다
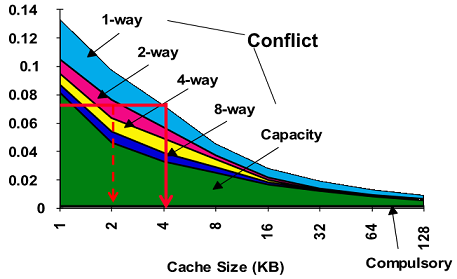
3Cs Relative Miss Rate
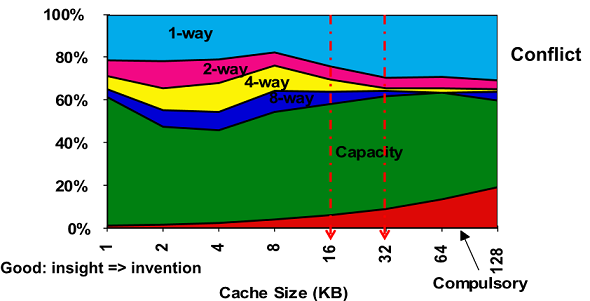
캐쉬의 용량이 늘어나면 miss는 줄어듬 Compulsory 는 비율은 상대적으로 커짐
어느정도 사이즈 크면 수렴하고 direct map(1-way)이 conflict 를 많이 발생시키는 특성이 있음
Capacity를 fully 로 보면됨
How Can Reduces Misses?
3Cs : Compulsory, capacity, conflict
total 캐쉬 사이즈는 변하지 않는다고 가정
- Block size를 변경 -> Block size 늘리면 compulsory는 줄어듬(entry가 줄어드니까), 다른 쪽으로도 영향을 주긴 줌
- Associativity 변경 -> conflict misses 가 달라짐
- Compiler 변경 -> conflict/capacity misses 다 바뀜
1. Reduce Misses via Larger Block Size
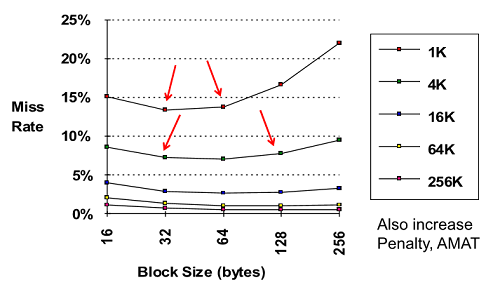
Block 사이즈는 줄다가 커지는 경향이 있음
miss가 줄어드는 것은 locality가 커지기 때문임
Block 사이즈 클수록 entry 개수가 줄어들어 후에 miss 증가
2. Reduce Misses via Higher Associativity
2:1 Cache Rule
miss는 좋아지는데 access time도 좋아질까?
hit time이 directed map에 비해 2-way로 하면 external cache의 경우 10%, internal의 경우 2% 증가함
-> associate 증가할 수 록 선택해야하는 block의 비교 시간이 증가함
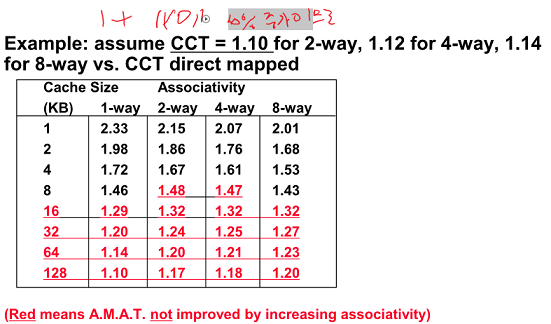
Associativity 가 클 수록 miss가 줄어들어 hit time이 줄어듬(넣을 공간이 많으니까)
근데 Cache size가 커질 수록 늘어나는 현상이 발생함
-> 용량이 커지면 miss로 인한 개인보다는 hit time 증가에 따른 오버헤드가 성능을 떨어트리는 요인임 (Associativity에 따른 비교 시간이 증가함)
Miss가 주는것보다 hit time 증가가 더 커지는 특성을 보임
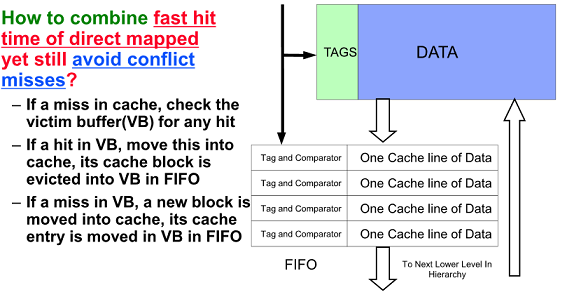
3. Reducing Misses via a Victim Cache
두개의 장점 결합 - Victim cache (Direct map의 빠름과 Associate의 miss rate 줄이는 장점)
Conflict 때문에 나가는 녀석을 Victim Cache에 넣고 위에 없으면 밑에 Victim Cache 조사 하여 hit
4개만 써도 20 ~ 95% conflicts를 줄임
빠른시간과 confilict miss를 잡는 효과적인 방법
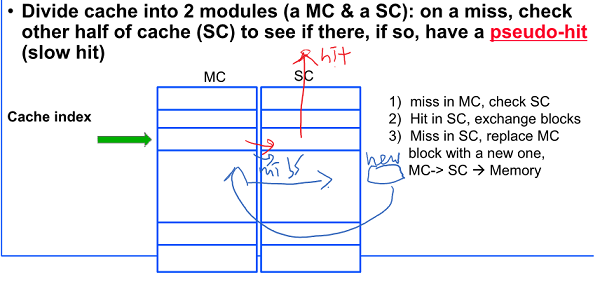
4. Reducing Misses via Pseudo-Associativity
Direct Mapped의 빠른 hit time과 2-way의 낮은 conflict misses를 지원하기 위해 Main cache, Shadow Cache로 Direct map 두개를 붙여놓은 것으로 보면됨
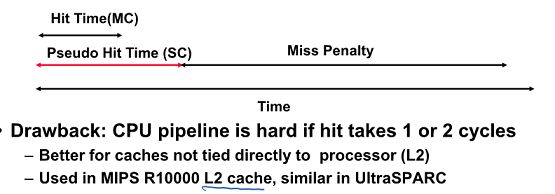
Hit time이 2가지로 나누어지므로 파이프라인 힘드므로 L2에서 만 사용
5. Reducing Misses by Hardware Prefetching of Instructions & Data
명령어는 대체로 순차적으로 돌아감(80~90%)
Data Cache는 miss가 많이 나는 편
미래에 사용되어질 명령어나 데이터를 미리 가져오는 방법
Prefetching 의 효과성 판단
Usefulness - 가져와서 진짜 썼는지
Timeliness - 늦지고 않고, 빠르지도 않게 가져왔는지
Cache의 bandwidth를 망치지 않았는지
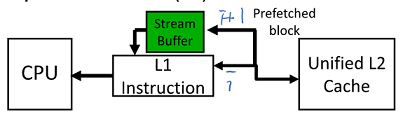
miss 난 block에 추가적으로 가져와 Stream Buffer에 집어넣음
Data block을 처리하는데 적용해도 괜찮은 결과 나옴
Why is this different from doubling block size?
Blocksize 증가로 인한 문제 없이 효과를 얻을 수 있음
6. Reducing Misses by Software Prefetching Data
Prefetch 하는 명령어들을 이용
7. Reducing Misses by Compiler Optimizations
Instructions
컴파일러 코드 재배치를 통해 software 로 miss 를 줄일 수 있음
Data
Merging Arrays - 배열 각각보다 struct 이용
Loop Interchange - Memory 저장 순서대로 데이터 access
Loop Fusion - 같은 arrays를 사용하는 for문 두 개를 하나로 합침
Blocking - 배열이 크면 부분 부분 계산 후 값을 저장
Summary

Reduce the miss penalty 로 넘어감
1. Read Priority over Write on Miss
Write 보다는 Read에 우선순위를 두어라
Write through
캐쉬에 무언가 쓰면 Memory에 똑같이 Write 되니까 바로 쓰지 못해 Write buffer를 두면 Cache에도 쓰고 Write buffer 도 쓰면 시간 될 때 Memory에 업데이트
캐쉬에다가 어떤 데이터 A를 썼을 때 Write Buffer 에도 A가 있을 텐데 Replace 가 된 상황에서 Read 하려고함 (Memory에 반영안됨)
RAW conflicts가 발생할 수 있다!
Wrtie buffer 가 쓸때까지 기다리는데 read 하려는데 Write buffer 에 써야하므로 시간이 길어짐
Read에 우선순위하면 Write buffer 에 있으면 Read 먼저하고 Write buffer 에 있는 내용 Memory에 씀
Write Back
Memory에는 안 쓰이는데 miss 나면 read를 하려고 했는데 업데이트 된 것이니까 read를 먼저하기위해 write buffer를 통해 read 먼저 하고 나중에 써야함
Dirty block을 wirte buffer 에 주고 read 수행 후 write
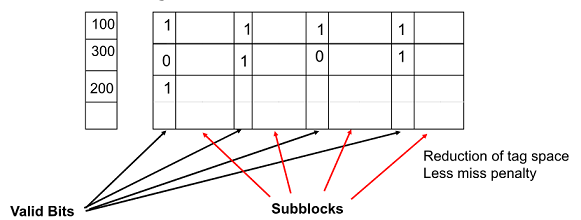
2. Subblock Placement
전체 full block을 load 하지말고 block을 sub로 쪼개 flag를 이용하자~
이를통해 긴 miss penalty를 줄임
3. Early Restart and Critical Word First
전체 block 을 기다리는 것이 아니라 필요한 부분을 먼저 load 해 사용
Early restart
처음부터 읽다가 보낼 것 만나면 보내주고 다음 꺼 읽음
Critical Word First
무조건 먼저 보내고 처음부터 읽음

block의 size 가 큰경우에만 적용 가능함
4. Non-blocking Caches to reduce stalls on misses
파이프라인 순서를 뒤죽박죽 수행할 수 있는 경우 사용
miss가 나도 다음 access 가 hit 하면 hit 를 support 함
(miss 가 나면 예전에는 기다림)
hit under miss -> 다음꺼 다음꺼가 또 miss 나도 다음 hit 지원
controller 복잡도가 매우 높아짐…
5. Secod Level Cache
L1는 빠른 hittime을 위해 direct map으로 되고 L2는 miss를 줄이도록 크게 설계
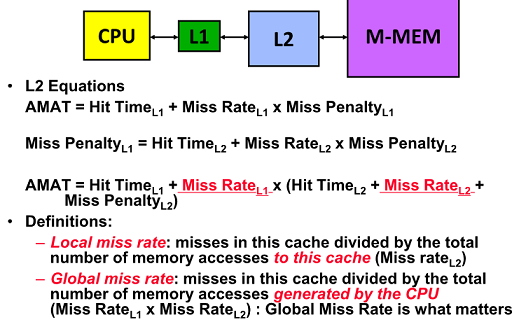
L1 : Small enough to reducce hit time
L2 : large enough to reduce miss penalty