Pipelining
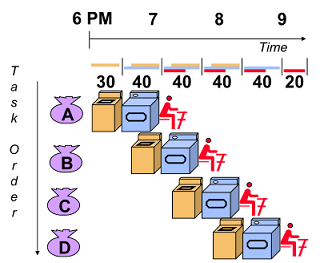
Pipelining 은 하나의 작업의 latency에는 도움이 되지 않음
제일 오래걸리는 stage의 제약을 받게됨(가장 slow 한 stage 에 제약을 받음)
여러개의 tasks 가 동시에 가동가능
가능한 최대 speedup은 stages의 개수에 달려있음
pip stages 의 길이들이 똑같지 않으면 speedup이 줄어듬
파이프라인을 채우고 빠지는 시간에 의해 speedup 이 줄어듬
Computer Pipelines
각 stage의 length 를 balance 하는 것이 목표
Speedup = Time on UnP/L / Time on P/L
많은 명령어들이 수행되기에 throughput이 목표임
DLX desirable features
1. 모든 명령어들은 같은 길이를 가지면 좋겠다
2. 명령어 포맷에서 같은 위치에 해당 레지스터를 표현할 수 있어야함
3. Memory operands는 load, store 만
DLS Instruction Format
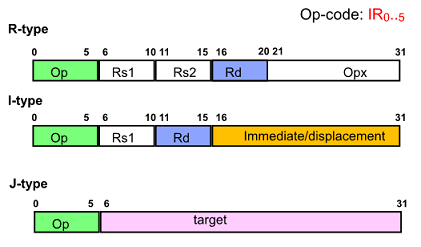
Simple Implementation of DLX
파이프라인 구조 설계를 위해 multicycle 구조로 필요한 부분을 구성해 보자
파이프라인이 없는 DLX 설계
- 각 단계를 한 사이클이 소요되면 여러단계에 여러 사이클이 가능한 multicycle design
- 5단계의 모듈로 구성되어짐
- 각 단계에서는 한 clock 사이클 소요되므로 모든 명령어는 5사이클이 소요되는 구조임
- 기본구조를 파이프라인 버전으로 만든 후에 쓰자
5단계의 모듈
IF(Instruction fetch) IF - PC에 저장된 메모리 content를 cpu로 읽어오는 동작
다음에 읽어와야하는 메모리 주소를 +4로 조정해줌(Next PC Count)
(IR - instruction register)
ID(Decode/Reg fetch)
ID - Risc 구조이므로 simple함 Source, Dst register의 수를 읽어서 연산을 준비함
EX(Execution/effective addrs)

memory ref 인 경우 A register content랑 imm을 더해서 effective memory address 를 뽑아냄
(imm은 signed extened 가 더해져 있음, IR - instruction register, NPC(PC+4))
R-R ALU instr 인 경우 A, B 를 읽은 것에 주어진 op를 통해 ALU해 저장함
R-I ALU instr 인 경우 한쪽은 register 다른 한쪽은 Imm으로 주어진 op 를 수행한 다음 저장함
C-BR 인 경우 조건이 충족 된 경우 target address 로 jump, NPC(pc relative 이니 현재의 NPC) 과 Imm 을 더해서 jump 해야하는 위치 계산
MEM(Mem access / completion)
loads/stores/BRS 인 경우만 active 함
WB (Write-back)
ALUOutput 한거나 LMD(Load memory data) 를 Register file 에 씀
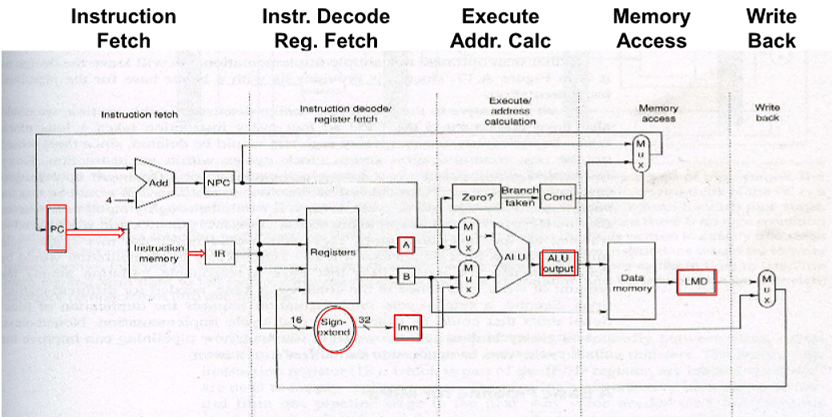
모든 명령어가 5 cycle 이 걸리는 simple 한 구조
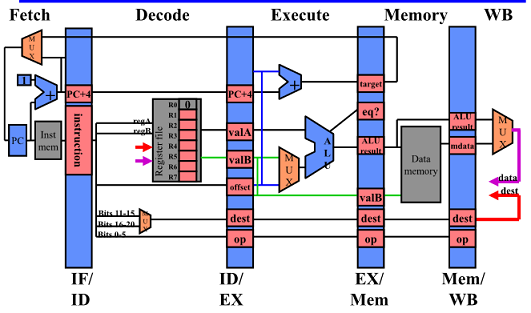
Pipelined DLX Datapath
위의 Simple 구조를 pipeline 구조로 만들기 위해 무엇이 필요할지?
각각을 독립적으로 동작시키기 위해 벽을 쌓으면 됨
-> stage 단계마다 pipeline register를 삽입(temporary register를 pipeline register로 이동)
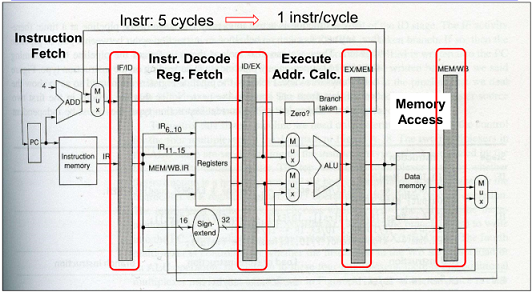
매 cycle 마다 1개의 instr이 나올 수 있게됨
DLX: Fetch Cycle
Instruction fetch cycle(IF)
- IR <- Mem[PC] : PC를 이용해 memory에 index 후 instruction 을 읽음
- NPC <- PC + 4 : PC 증가
위의 값을 모두 pipeline register(IF/ID) 에 Write
- 다음 stage에서 이 pipeline register 값을 읽음
- 파이프라인 레지스터는 클럭을 모두 동일하게 맞추어 설정
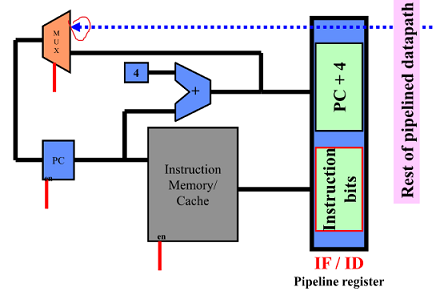
빨간부분 read/write signal
64bit 면 끝남
DLX: Decode Cycle
IF/ID pipeline 레지스터에서 읽어 instruction을 decodes 해 register file에서 읽음
Decode/Reg fetch cycles(ID)
- A <- Regs[IR6…10]
- B <- Regs[IR11…15]
- Imm <- (IR16)^16 ## IR(16…31)
- A, B, Imm : temp Register
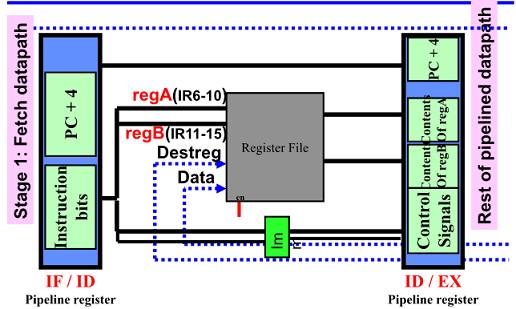
검은 줄은 32bit 의 wire 임
128bit 필요
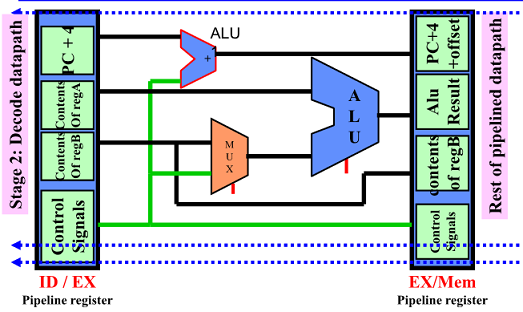
DLX: Execution Cycle
ID/EX pipeline register 에 있는 values 를 통해 적절한 ALU 계산을 수행함
Input은 regA 와 regB or offset field 임
또한 branch일 경우 PC+4+offset 이 계산됨
Execution/effective addrs cycle(EX)
target address는 ALU 하나 더 두어 계산(jump 수행을 빨리하기 위해 리소스를 더 사용)
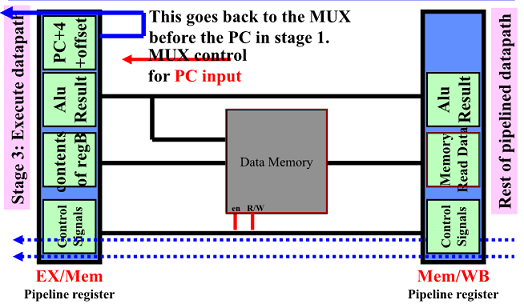
DLX: MEM Cycle
EX/Mem pipeline register에 존재하는 값을 통해 적절한 memory 연산 수행
- ALU 결과는 Load, store instructions을 위한 address를 가짐
- Opcode 를 통해 memory R인지 W 인지, enable signals를 제어함
Mem access/completion cycle(MEM)
- Mem ref: LMD <- Mem[ALUOutput] or Mem[ALUOutput] <- B
- BR : if (Cond) PC <- ALU1 else PC <- NPC
DLX: Write Back
instruction 실행을 완료하는 단계이며 필요할 경우 register file 에 write
- load 명령어 시 destReg에 MemData를 Write
- add or nand 명령어 시 destReg에 ALU 결과를 Write
Write-back cycle(WB)
- R-R Instr: Reg[IR16…20] <- ALUOutput
- R-I ALU instr: Reg[IR11…15] <- ALUOutput
- load instr: Reg[IR11…15] <- LMD
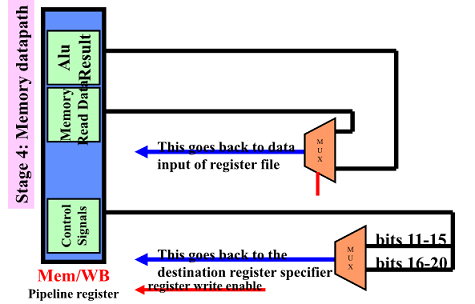
R, I type 에 따라 bit 11-15를 쓴 것인지 16-20 을 쓸 것인지 결정
DLX: Pipeline Structure
Visualizing Pilelining
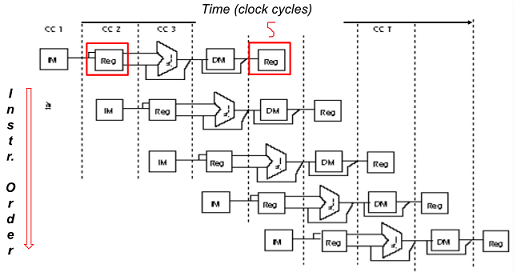
매 사이클 마다 1개의 명령어의 결과가 나올 수 있음