Dictionary data structures
Parsing a Document
Inverted Indexes는 Dictionary 데이터 구조를 가짐
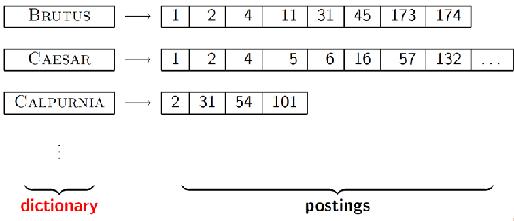
dictionary data structure는 term 단어, 문서빈도수, postings list의 pointer들을 저장한다.
어떤 data structure로 저장할 것인가?
두가지 choices:
Hashtables - 단어가 있는지 없는지 보기 편함
Trees - Search가 가능(locality가 보존가능함)
Hashtables
각 단어 term을 하나의 int(고유번호)로 hash 시킴
장점
- O(1) 만에 빠르게 검색가능
단점
- 적은 변형이 일어날 경우 찾기 어려움(ex. judgment/ judgement -> 같은 해쉬 값을 가질 것임)
- prefix search 가 불가능(Wild-card 연산 불가능 ex. automat* : automatic, automaiton, …)
- 단어가 계속 추가되어야 하면 전체에 대해 rehashing이 일어나야함(비용이 비쌈)
Tree
간단한 binary tree와 자주 쓰이는 B-tree 존재
장점
- prefix 문제를 해결가능(예를들어 hyp로 시작하는 단어 검색 가능해짐)
단점
- balanced tree 여도 O(logM)으로 느림
- binary tree를 rebalancing 하는데 매우 비쌈
한쪽으로 치우쳐진 트리형태는 검색 비용이 O(M)이 되기 때문에 안좋음
Tolerant Retrieval(정보검색을 유연하게)
Wild-Card Queries : *
mon* : mon으로 시작하는 단어를 포함하는 모든 문서를 찾는 것
쉬운방법으로는 binary tree(or B-tree)를 이용해 mon ≤ w < moo 범위안의 모든 단어를 보면됨
그러나… *mon과 같이 거꾸로 되어 있다면?
B tree를 역순으로 만드는 방법도 있겠지만 co*tion 과 같이 중간에 삽입되는 경우도 존재
일반적인 해결방법은 Permuterm Index를 이용하는 것임
Permuterm Index
hello라는 term이 있을 때 index를 hello$, ello$h, llo$he, lo$hel, o$hell, $hello 와 같이 locate 해서 여러번 집어 넣음
예를 들어 Queries가 아래와 같다면 각각의 locate에 맞는 index를 찾아가면됨
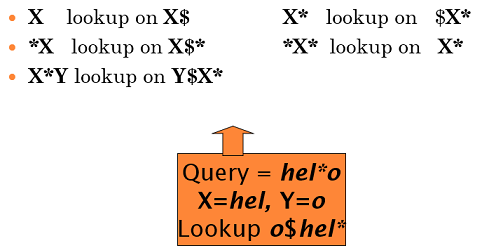
Spell correction
Spell 수정이 사용되는 곳
1 문서가 정확하게하여 정확한 indexed 되도록 하기 위해
dictionary에 missspelling 되는 것을 적게하는 것이 목표
특히 OCR 문서 같은 곳에 필히 필요로됨
그러나 documents 자체를 변경하기 보다는 query-document mapping을 변경하는 경우가 많음
2 user queries를 정확하게 하여 정답을 알려주기 위해
잘못된 질의를 물어봄(Did you mean…?) - 의도한 것이 고쳐진 것이였는지
Iphone 같은 경우 물어보지 않고 바로 고침
Isolated word
- 단어 자체에 대한 spelling 체크를 하는 것
- ex. from -> form
Context-sensitive
- 주변단어들을 고려해서 봤을 때 뜻이 맞지 않는 것을 찾아내는 것
- ex. I flew form Heathrow to Narita
- 위의 문장의 form이 from이 되는 것이 맞음
Isolated Word Correction
lexicon(어휘목록, 사전)이 주어졌을 때 character sequence Q에 대해 lexicon안에서 Q와 가까운 단어를 return 해줌
3가지 방법 존재
- Edit distance(Levenshteien distance)
- Weighted edit distance
- n-gram overlap
Edit distance
키보드 타이핑하다 실수했을 것이다 가정
두개의 String 이 주어졌을 때 하나의 string을 다른 하나의 string으로 변경하는데 최소방법으로 고친 operation의 수를 둘의 유사성을 나타내는데 사용
각 operation에는 character-level로 Insert, Delete, Replace 존재
ex)
- dof to dog is 1
- From cat to act is 2
- From cat to dog is 3
일반적으로 dynamic programming을 이용해 찾음
Weighted edit distance
삭제, 삽입을 같은 weight를 주는 것도 맞지 않고, 자주 mis-typed 하는 것에 더 많이 가중치를 주고 싶을 때 Weighted Edit Distance 이용
N-gram overlap
novermber, december가 가까운 단어인지? - trigram을 이용함

3개의 trigrams가 overlap됨(각각 6 term이 존재하는 상황에서)
overlap되는 양을 query와 text 사이에서의 유사성을 나타내는데 사용
One option - JACCARD COEFFICIENT
N gram으로 쪼개 단어간 차이 확인 시 가까운 단어들 빨리 찾는 법
overlap 방법에 종종 사용됨
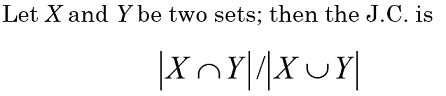
J.C 값이 1이면 X와 Y는 모두 같은 N gram으로 쪼개진 element들을 가지고 있어 매우 가까움
0은 서로 완전 다른 단어이며 0~1 사이 값으로 할당됨
threshold를 정하여 J.C > 0.8 이면 match이다로 판단함
Context-Sensitive Spell Correction

모든 단어들이 사전에 있지만 의미상 form을 from 으로 바꾸어야함
Probabilistic Language Models
Language Model
input - LanguageModel - output이 있을 때 output이 높을 수록 확률적으로 좋은 것
words sequences에서 확률적인 분포를 나타냄
sentence에 확률을 할당함
1 기계 번역
P(high winds tonite) > P(large winds tonite)
영어로 번역할 때 해당 문장에서는 large 보다 high로 쓸 확률이 높음
따라서 high로 번역
2 Spell Correction
The office is aobut fifteen minuets from my house라고 오타가 있을 때
P(about fifteen minutes from) > P(about fifteen minuets from) 이므로 minutes 가 맞냐고 질의한 사용자에게 물어보거나 고침
3 Speech Recognition
P(I saw a van) » P(eyes awe of an)
사용자가 말한 것을 인지할 때 발음이 비슷한 것들에 대해 확률이 높은 문장을 택함
목표 : sentence나 sequence of words를 확률로 계산
P(W) = P(w1, w2, … wn)
| P(W) or P(wn | w1,w2…wn-1)을 language model이라 부름(LM) |
How to Compute P(W)
P(its, water, is, so, transparent, that)
joint probability를 어떻게 구할 것인가?
일반적으로 chain rule 이용

그러나 아래 그림과 같이 너무 복잡함
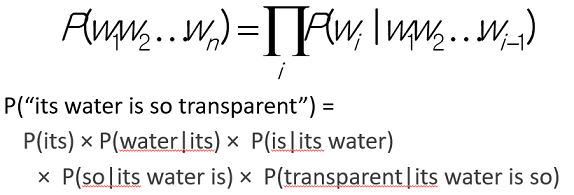
Markov Assumption
chain rule 다보려면 history 길어서 마지막만 보겠다가 Markov Assumption

Soundex
여태까지는 타이핑과 관련되었고 이제부터는 사운드 관련 이슈임
발음이 동일한 질의를 어떻게 heuristics 하게 분리할 것인지?
비슷한 사운드 끼리는 같은 숫자를 주고 모음은 탈락 시키는 것이 일반적인 알고리즘


soundex가 information retrieval에서는 매우 유용하지는 않음