Document
Parsing a Document
문서 각각의 언어 및 형식을 다루어야함
형식 -> pdf, word, excel etc.
언어는 무엇인지, character set은 유니코드인지 멀티 바이트인지 등 classification 문제가 존재
대안으로 휴리스틱 이용
Format/Language : Complications
하나의 index가 여러 언어를 포함할 수 있음
- Spanish pdf 가 붙여진 French email
XML, 파일 그룹?
여러 다른 포맷, 언어들을 다루기 복잡함
Terms
Definitions
Words - text에 나온 string
Term - normalized 된 word(upper case, lower case 제거, 형태학적으로 같은 클래스에 속한 word들을 대표 word로 변경), distinct 한 단어
Token - document 에서 나오는 word or term들의 instance, mulitple times 등장 가능
Type - 보통 term 과 같으며, tokens의 class와 동일함
Token vs Type
The term “token” refers to the total number of words in a text, corpus etc, regardless of how often they are repeated. The term “type” refers to the number of distinct words in a text, corpus etc.
“a good wine is a wine that you like” contains nine tokens, but only seven types, as “a” and “wine” are repeated.
Normalization
text와 query에 normalize할 필요가 있음
EX. We wnat to match U.S.A. and USA
대부분 경우 terms 의 동등한 클래스를 암시적으로 정의함
window -> window, windows windows -> Windows, windows Windows
powerful하지만 효용성이 적음
같은 MIT 이지만 다른 뜻을 가짐(언어가 다름에 따라) PETER WILL NIGHT MIT He got his PhD from MIT
Tokenization problems: One word or two?
- Hewlett-Packard
- co-education
- San Francisco
위의 단어들을 하나로 볼지 둘로 볼지?
Numbers
- 3/20/91
- Mar 20, 1991
Chinese에는 공백이 없어 어떻게 tokenize 할 것인지?
Arabic은 양쪽 방향으로 읽음(Bidirectionality)
Case folding
모든 단어를 lower case로?
Stop words
자주 사용되는 단어들에 대한 처리
ex) a, an, and, are….
More equivalence Classing
의미적으러 같은 단어(car = automobile)
Lemmatization(분류정리)
변형된 형태를 base 형태로 바꾸어줌
ex) am, are, is -> be
ex) car, cars, car’s -> car
문장속에서 다양한 형태로 활용된 단어의 표제어(lemma)를 찾는 일
표제어란 ? 사전에서 단어의 뜻을 찾을 때 쓰는 기본형
아름다운 이 Lemmatization을 거치면 아름답다가 된다.
Stemming
뒤의 단어를 제거해버리는 heuristic한 프로세스
ex) automate, automatic, automation 은 automat가 됨

Porter algorithm
영어에서 일반적으로 잘 알려진 어근 추출 방법
단어의 접미사를 제거하거나 다른 단어로 대치하는 역할을 하는 알고리즘
- cats → cat
- caresses → caress
- conflated → conflate
- troubling → trouble
- relational → relate
A few rules

Does stemming improve effectiveness?
일반적으로 stemming은 어떤 query에서는 effectiveness 하지만 다른 것에서는 effectiveness를 감소시킬 수 있음
‘oper’ class는 operate, operating, operates, operation, operative 등 을 모두 포함할 것임
Skip pointers
Recall basic intersection algorithm
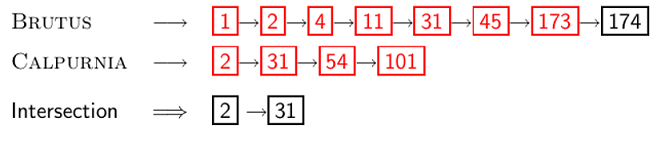
두개의 pointer를 이용하여 Linear 하게 search
더 나은 방법은??
Skip Pointers
posting을 skip 하는 방법
**어디에 skip pointer를 넣을 것인가? **
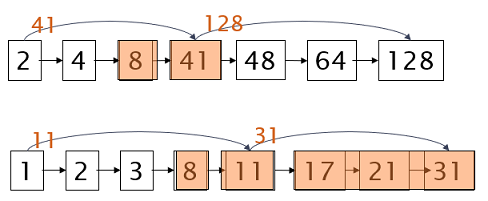
두개의 posting 리스트에서 8 다음에 41, 11임
11이 더 작으므로 11의 skip pointer를 이용하여 31로 바로 넘어갈 수 있음
Tradeoff
skips을 많이 넣을 경우 -> skip의 span이 줄어듬
But skip pointer의 많은 비교가 필요…
skips가 적을 경우 -> skip span이 너무 김
skips를 성공할 확률이 적음
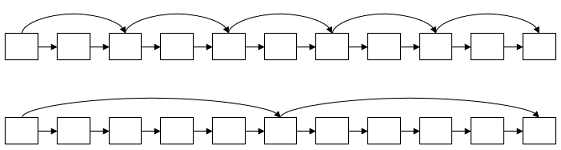
Simple heuristic : posting의 길이가 P라 할때 skip pointer를 √P 만큼 배치한다면 logN 정도로 탐색을 줄이는 효과를 볼 수 있음
skip pointers가 많은 도움이 되지만 오늘날과 같이 CPU가 빠른 환경에서는 더이상 효과가 없음 -> Linear하게 보는게 더이상의 이슈가 안됨
Phrase queries
Phare queries
stanford university 라는 질의의 답을 원한다고 가정
The inventor Stanford Ovshinsky never went to university 는 매칭되지 않음 -> Stanford와 university가 떨어져 있어서
이를 해결하기위한 inverted index의 확장 버전
- biword index
- positional index
Biword indexes
terms의 연속된 쌍을 Index로 만듬
ex) Friends, Romans, Countrymen 이라면 “friends romans” 와 “romans countrymen” 이라는 두가지 가 생김
Longer phrase queries 에 대한 처리도 필요
“stanford university palo alto” 같은 질의에서 4개의 단어가 포함됨
Biword로 는 불가능
Extended biwords
N - nouns
X - articles / prepositions
NX*N from으로 extended biword 사용 가능
cacher in the rye = N X X N
king of Denmark = N X N
Issues with biword indexes
왜 적게 사용하는가?
False positives 함
Index 가 많은 term vocabulary에서는 매우 많이 생김
Positional indexes
posting 리스트에 doc id와 position에 관한 정보가 포함됨

<> 안에 있는 것들이 position
To, Be가 모두 1, 4에 나오지만 to 다음 be가 나오는 document 는 4밖에 없음
Proximity search
ex) employment /4 place
document에서 Emplyment 와 4단어 안에 place 가 위치한 문서를 찾는것

positional index를 이용하는 검색
frequent words 특히 stop words에는 inefficient 함
Combination scheme
Biword index와 positional index를 적절하게 결합
positonal query는 Boolean 보다 훨씬 비용이 비쌈