Introduction
Information retrieval
정의 - 많은 양의 정보로부터 필요한 정보를 만족시키는 비구조적 text 문서를 찾는 것
HOW GOOD ARE THE RETRIEVED DOCS?
Precision - 사용자가 필요로 하는 정보와 연관된 문서의 비율
Recall - 가져온 컬렉션의 관련 문서의 비율
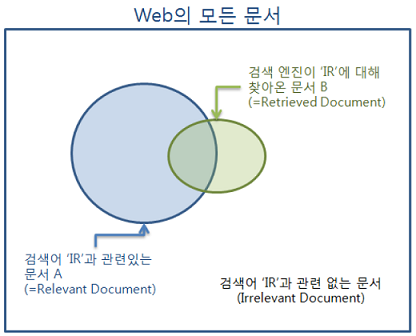
정확도(precision) = 갯수(A∩B) / 갯수(B)
= 시스템이 찾아온 것 중 정답인 비율 = 오답을 찾지 않을 확률
재현율(recall) = 갯수(A∩B) / 갯수(A)
= 실존하는 전체 정답 중 정답인 비율 = 존재하는 정답을 얼마나 재현할 수 있는가, 얼마나 많은 정답을 찾는가)
Boolean retrieval
정보검색에 있어서 가장 기본적인 모델 Query들이 Boolean으로 표현됨 (ex. CAESAR AND BRUTUS)
Does Google use the Boolean model?
YES!
구글에서 질문[w1, w2, …, wn]을 해석할 때 default 로 w1 AND w2 AND … AND wn 으로 해석
wi 를 사용할 수 없는 Case(Boolean Model은 제한적으로 사용)
- anchor text(Plain text 보다 의미있는 단어임)
- wi의 변형이 page에 존재하는 경우(delete, deletion..)
- n이 매우 클 경우
- Boolean Expression이 매우 적게 hit 할 경우
Boolean retrieval에서는 Set of Document 가 return 됨 -> 집합이라 순서가 없음
Google(Boolean engines 이 잘 디자인된)은 Result set에 Rank를 매김 -> 높은 hits 일 수록 좋은 rank를 가짐
Inverted Model
Unstructured data in 1650
Shakespeare 연극에 BRUTUS AND CAESAR but not CALPURNIA?
grep을 이용해서 BRUTUS and CAESAR를 찾고, CALPURNIA를 포함한 줄을 제거
grep -> 유닉스 계열 파일 문자열 탐색 기능
grep은 좋은 솔루션이 아님
- collections가 크면 매우 느림
- grep는 line 기반이며 IR은 문서기반임
- NOT CALPURNIA를 처리하기 쉽지 않음
- 예를들어 ROMANS와 가까이 COUNTRYMAN 이라는 단어를 찾는 것은 실현 불가능함
grep 말고 다른 접근법 필요
Term-document incidence matrix
document에 term이 나왔는지 안나왔는지 binary로 표시

bit 연산으로 찾기 쉬워짐
각 term을 0/1의 vector로 표현하고 BRUTUS AND CAESAR AND NOT CALPURNIA 질문이 있다면
110100 AND 110111 AND 101111 = 100100

Bigger collections
N = 10^6 documents 이고 각각 문서에 1000 tokens 들이 있다고 가정 => total of 10^9 tokens
하나의 token에 6byte가 필요하다면 6*10^9 이므로 6GB 필요
Can’t build the incidence matrix
M = 500000의 distinct 한 terms 가 있다고 가정
대부분이 0이면 Matrix는 매우 sparse함
좋은 대안은 ? 1인 record만 기록하는 것임
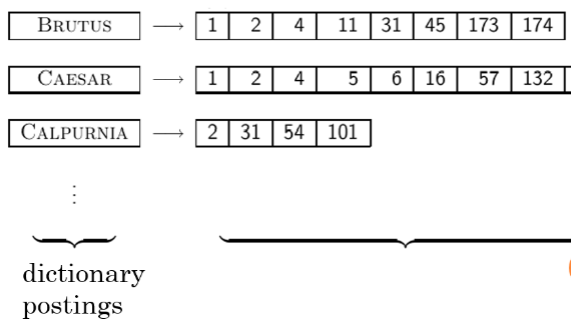
Inverted Index
dictionary와 postings(document id) 로 구성
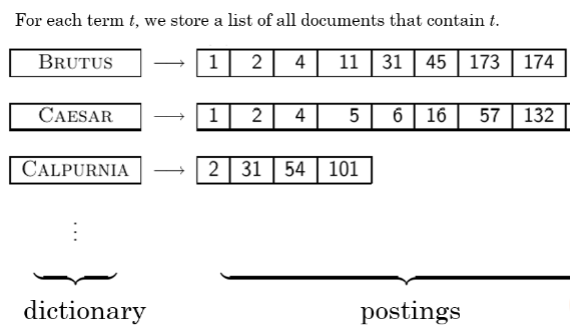
BRUTUS는 document 1, 2, .. 174에 포함된다는 뜻
INVERTED INDEX CONSTRUCTION
- 색인을 생성할 문서 수집
- 각 문서의 text를 Tokenize 함
- linguistic 전처리 과정을 거침(normalized tokens)
- Friends -> friend로 소문자로 변경
- 각 term 이 발생된 documents 들을 index하여 inverted index 구성
INITIAL STAGES OF TEXT PROCESSING
- Tokenization
- charater sequence를 word 단위 토큰으로 자름
- Normalization
- text와 query term을 같은 모양으로 변형
- You want U.S.A and USA to match
- Stemming
- 다른 형태의 단어의 root를 매칭 시킴
- authorize, authorization
- Stop words
- common words는 보통 생략함
- the, a, to, of
Tokenizing and preprocessing
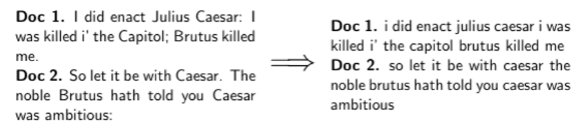
Generate and Sorting postings
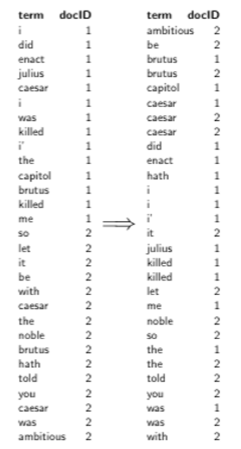
Create postings lists, determine document frequency

Split the result into dictionary and postings file
Processing Boolean queries
Simple conjunctive query
BRUTUS AND CALPURNIA 쿼리라 가정
Inverted Index를 이용해 찾기
Dictionarhy에 BRUTUS 위치를 찾아감
posting file에서 BRUTUS의 postings list를 가져옴
CALPURNIA 위치를 찾감
posting file에서 CALPURNIA의 postings list를 가져옴
두 list의 교집합을 user에게 리턴
Intersecting two posting lists
두 리스트에서 교집합 찾는 좋은 방법은 sorting -> Linear 접근
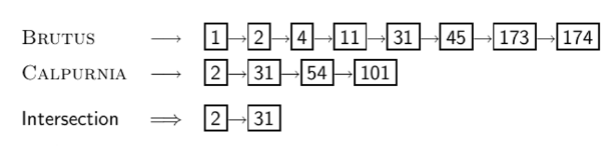
더 크면 안봐도 되는 장점(선형적으로 탐색 가능)
Commerically successful Boolean retrievals:Westlaw
query : “trade secret” /s disclos! /s prevent /s emplye!
Proximitiy operators: /3 = 3 단어 아내에, /s는 같은 문장, /p 는 같은 단락 안에 또 다른 단어 찾을 수 있음
Boolean search는 precision, transparency, control 하기 때문에 도서관 등 아직도 사용되는 것이 많음
Query optimization
Query optimization
query term 이 두 개 이상일 경우
ex) BRUTUS AND CALPURNIA AND CAESAR
어떤 순서로 먼저 하는 것이 좋을까??
shortest positngs lsit 부터 하는 것이 가장 빠름
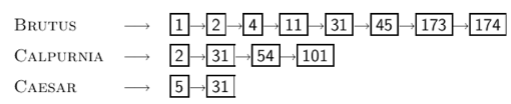
CAESAR 부터 보면 31 까지만 보면됨
More general optimization
Exampel : (MADDING OR CROWD) and (IGNOBLE OR STRIFE)
all terms의 frequencies를 가져옴
각각의 () 마다의 frequencies를 더해서 size 측정
사이즈가 증가하는 순서대로 수행(작은 것 부터 수행)