AI 논문리뷰 - ACL/언어
Main Conference 주요 주제
- LLM Observations
- Data Collection/Benchmark
- LLM Fine Tuning
- Audio, Speech, Multimodal
- Prompting
- Data Augmentation, Continuous Pretraining, Non-LM, …

ACL Review 주제 구성
- LLM Pretrainig / Fine Tuning 기반 기술
- 효과적인 LLM 학습을 위한 모델 구조 변경
- 효과적인 학습을 위한 데이터 구성
- LLM Embedding 기반 기술
- Top Embedding 중 하나인 BGE-M3를 비롯하여, 최신 임베딩 모델들에 대해 이해
- 임베딩 파인 튜닝 과정 이해
LLM Pretraining / Fine Tuning
Main Research Questions
어떻게 Catastrophic Forgetting을 장지할 수 있을까?
도메인 특화 / 멀티 태스크 데이터를 어떻게 효과적으로 학습시킬까?
Notable Research : LLAMA-Pro, PIT
Catastrophic Forgetting
일반적으로 새로운 도메인의 코퍼스를 사용해서 Continious Pretraining : 사전 학습 모델을 추가 학습 시키기
Code-Llama, llemma(수학 잘하는) 등의 모델의 경우 기존의 지식을 크게 손상시키는 Catastrophic Forgetting 발생(기존 지식을 까먹음)
이유는 Pretrain 분포와 새 데이터의 분포가 매우 다르기 때문에, 이를 반영하는 과정에서 큰 변화가 생김
그럼 Pretrain 이후의 학습을 안전하게 할 수 없을까?
- LoRA 등 PEFT 학습의 경우, Continuous Pretraining에서의 성능은 좋지 않음 LoRA Learns Less and Forgets Less” 논문
-> 근본적으로 Transformer 구조를 그대로 활용하면서 Continuous Pretrain을 효율적으로 하는 방법이 필요
Block Expansion : 새로운 블록에 도메인 지식 넣기
Pretrained 모델을 특정 도메인에 적용 시키기
- 기존 블록 Freeze후 새로운 디코더 블록 추가
- M x N 사이에 P 개의 Block을 추가(중간 중간에 끼움)
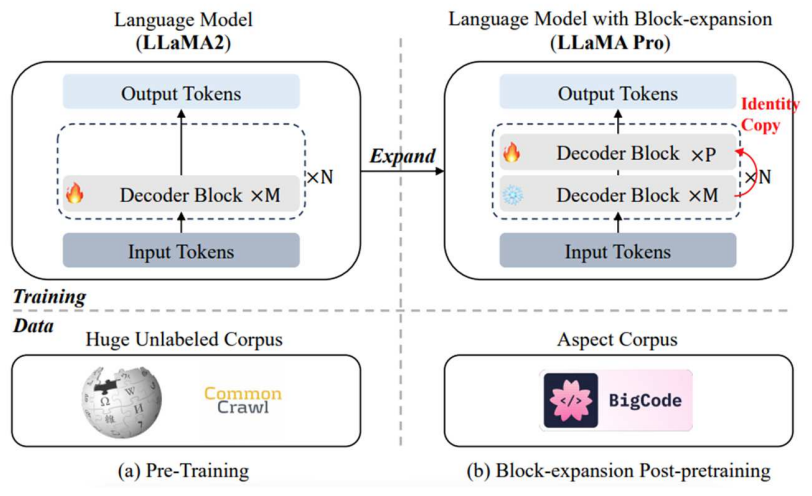
- Llam-PRO: Llama2-7B에 8개 블록 추가하여 Catastrophic Forgetting 없이 성능 향상 확인
- But 중간에 넣는데 Python, Math 풀 때 영향이 정말 없는지 의문
- 32개에 8개만 25% 정도 추가로 붙였는데 param 변화해보면서 실험도 가능
추가 block은 중간에 붙일 때 실험 결과가 좋았음
모델 전반적으로 골고루 전달하는 효과
Residual Connection 구조로 쉽게 해볼 수 있는 아이디어
Llama2-Pro Korea라고 이미 다국어로도 효과적으로 학습된 모델 존재
논문의 강점
- Post-pretraining 관점에서 효과적인 적용 방식
- 중간에 freezing 시키고 몇 개만 학습시키는 요즘 트랜드(야놀자 EEVE 학습 방법과도 연관이 있음)
- LoRA 보다는 근본적인 개선?
개선점
모델의 작동 방식을 좀 더 깊에 고려한다면 Block 배치나 최근 모델에 맞춰서 추가 연구 필요
Self-Distillation Fine Tuning: 데이터 레벨에서의 개선
새로운 데이터와 기존 모델의 분포 차이를 줄이는 방법
새로운 데이터의 내용은 유지하면서, 목표 LLM의 성능에 맞게 프롬프트를 수정하는 방법 -> Self-Distillation
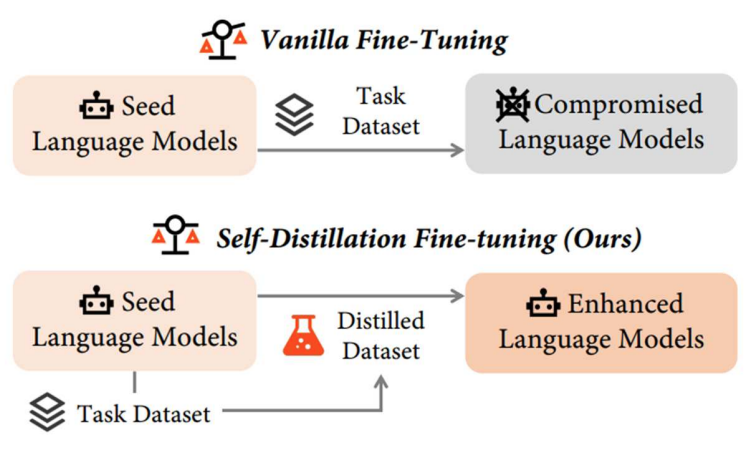
Task Dataset을 Seed Model에 물어보고 data 분포를 수정해서 학습
데이터 모델을 LLM에 Projection 시킴

단순 파인 튜닝 대비 성능 향상 + General Knowledge 보존
비슷한 분포 유지 + Safety 능력 유
논문의 강점
- 높은 범용성 과 데이터 전처리에 대한 문제도 해결 가능
- 누가 보기에도 한국어로 번역된 수준 떨어지는 데이터를 LLM에 넣어 답변을 다듬어 주는 효과 확인
개선점
- 모든 상황에서 정말 가능한지, 검증 및 필터링 메커니즘이 어려움
- 모르는 데이터에 대해 Seed 모델이 잘 대답 못할 가능성이 있음
Self-Synthesized Rehearsal: 효과적 Multi-Task Learning
여러 개의 Task를 학습시키는 경우, 이전 Task 지식을 망각하는 문제
- Rehearsal Training: 직전 단계에서 공부한 데이터를 포함하여 추가 학습
Challenges : LLM에서는 이전 데이터를 얻기 힘들고, 데이터의 대표성을 보장하기 어려움
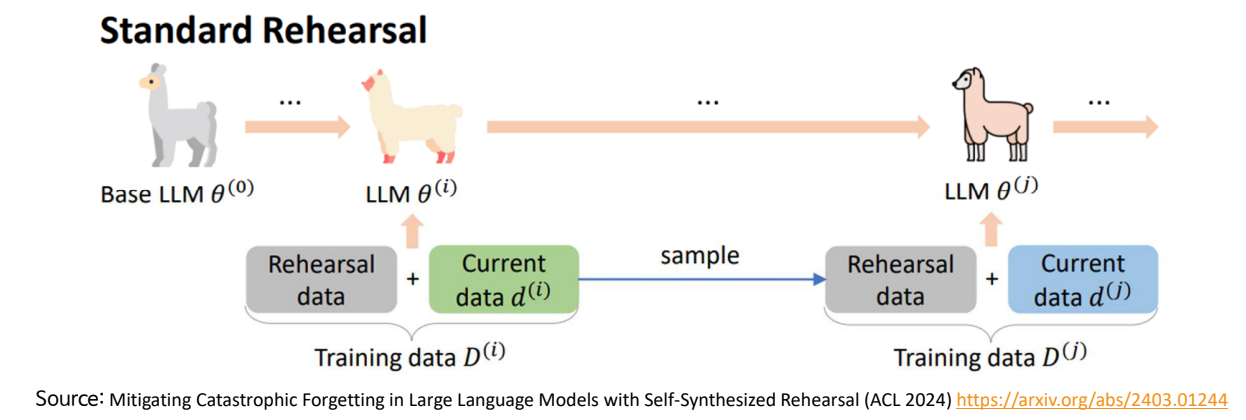
어떻게 해야 복습을 잘할 것 인가?
Self Synthesized라고 Base LLM으로 부터 데이터를 스스로 생성
생성한 데이터를 정제하고 클러스터링하여 다음 학습 데이터에 합쳐서 학습
여러개 테스크 학습 시킬 때 과거를 까먹지 않고 학습을 잘 할 것이다.
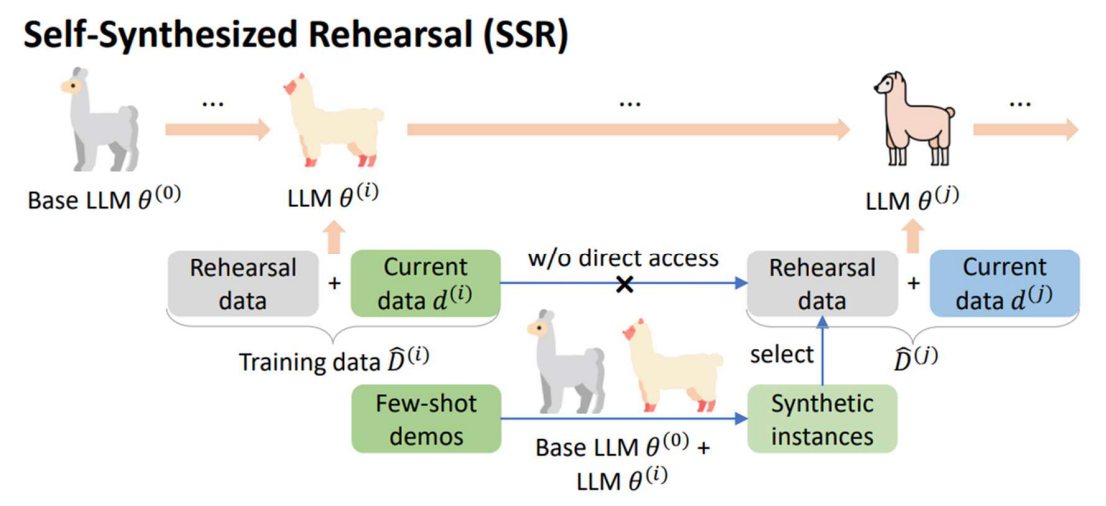
강점
- Catastrophic Forgetting을 해결하는 방법 제안
- Multi-task Learning에서 유용한 활용 가능성
개선점
- 실험이 약간 부족
- 모델 자체의 성능에 의존
- Self-Distillation 과 비교했을 때 덜 매력적
Pre-instruction-tuning: Domain 지식 효과적 학습
Pretrained 모델을 Domain-Specific으로 만드는 과정
- 추가 Pretrain -> QA Tuning
- Observation : 문서의 PPL Score는 줄이지만, QA 성능이 좋지 않았다.
Continued pre-trainig과 QA instruction-tuning 정확도가 떨어짐
학습을 시키기 전에 먼저 QA를 공부를 시킴(doc를 보기 전에 Pre-trained LM)
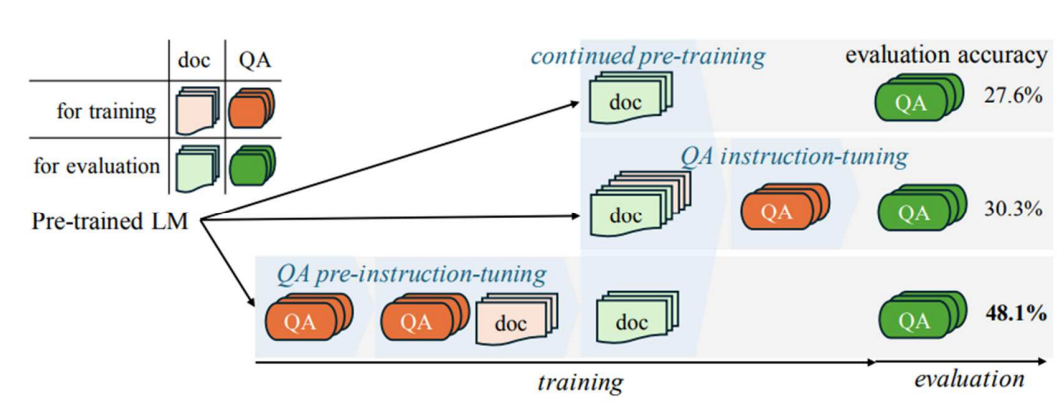
QA로 단편적으로 학습된 지식이 Pretrain 과정에서 정리 될 것이다
Pre-Instruction Tuning(PIT) : 순서를 바꾸면 성능이 좋아진다.
Instruction-tuned Language Models are Better Knowledge Learners (ACL 2024)
PIT ++ -> QA Trainig 이후 QA-Document를 혼합학습
Wikipedia에서 효과적인 성능을 보임
논문의 강점
- Simple하지만 효과적인 성능 향상
- 다양한 도메인에서 활용될 수 있는 가능성
개선점
- 이론적인 추가적 고찰이 있었으면 좋겠음
- Wikipedia QA 데이터는 제한적
- 작은 모델에서도 제대로 동작할까?
LLM unLearning -> 배운걸 잃어버리게 하는 것도 연구 되고 있음