컴퓨터 비전 심화과정 박충현 패스트캠퍼스 3D 강의 참고 정리
PointTransformer
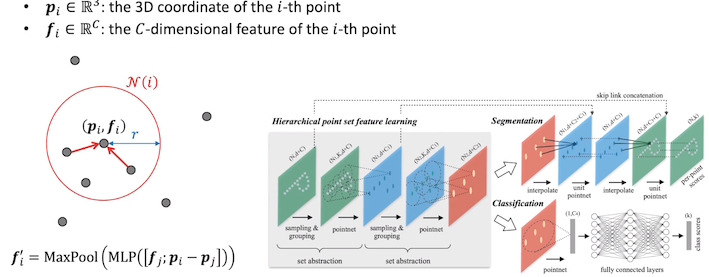
PointNet-Overview
Input Points가 들어오면 rotation과 같은 transform 이 있으며로 input transform 을 거친 후 shared MLP를 이용해 featrue transform을 거치고 symmetric을 위한 global feature를 추출하게 됨
이를 mlp에 넣어 classifation을 하거나 n x 64와 concat 시켜 segmentation에 활용
PointNet은 locality가 없어 연산량이 많고 보지 못한 scene에 대해 성능이 낮음
Locality in Point Clouds
- Neighbor search algorithms
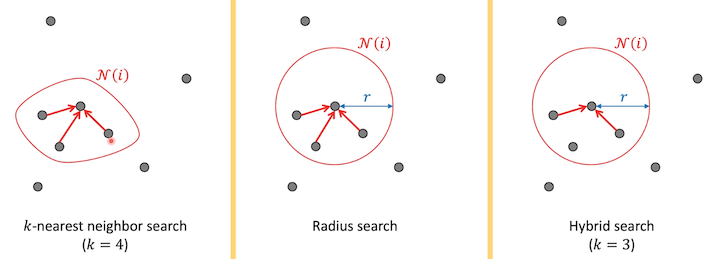
radius 안에 들어간 points 중 가장 가까운 것 찾음
이런 Locality를 이용해 PointNet에 locality 특성을 추가한게 PointNet++ 임
PointNet++
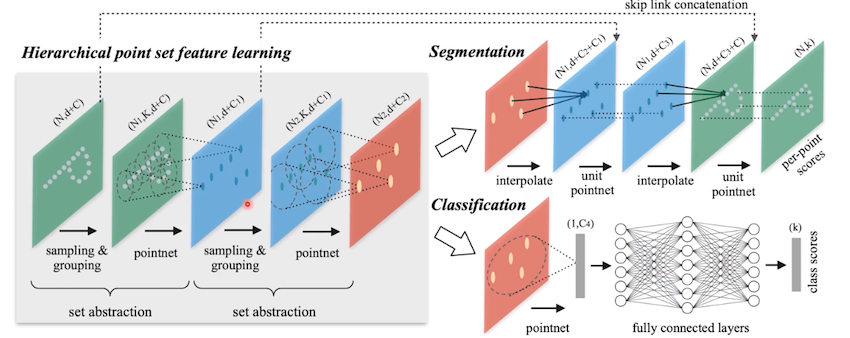
- Sampling : Farthest point sampling 을 이용
- Grouping : Hybrid Search 사용
Sampling & Grouping
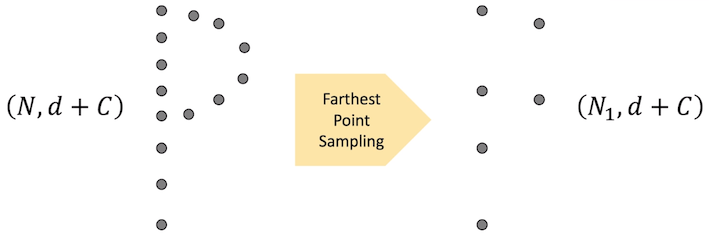
Farthest point sampling
- N, N1 : sampled 포인트 갯수(N > N1)
- d : point의 차수(usually, 3)
- K : 이웃 포인트 갯수
- C, C1 : featrue map의 채널
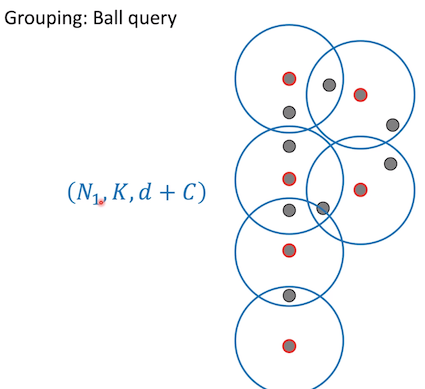
Grouping : Ball query
radius 안의 3개의 점이 하나로 표현
3개가 넘으면 버리고 적으면 padding을 넣어 shape은 3을 유지 시켜 연산 편리 제공
PointNet을 각각 거쳐 차원을 줄임
Upsampling
Encode 단에서 feature를 skip concatenation 해서 upsampling을 함(전반적으로 2d UNet과 유사)
PointNet++ vs Point Transformer
PointNet++
Sampling된 point 중심에서 local 이웃을 찾고 중심과 point의 relative vector을 concat하고 MLP를 통과 시켜 symmetric Function인 maxpooling을 진행함
local Neighborhood 정의와 연산이 다름(KNN이용)
Point Transformer
local Neigborhood를 SelfAttention 과 Sum을 통해 계산
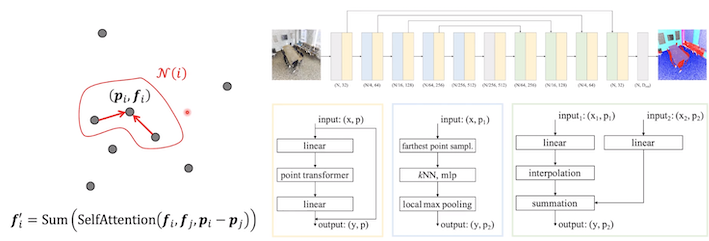
Local Self-Attention
- convolution이 가운데 들어오는 feature에 따라 kernel의 weight가 바뀌는 dynamic kernel weights 특성을 가짐
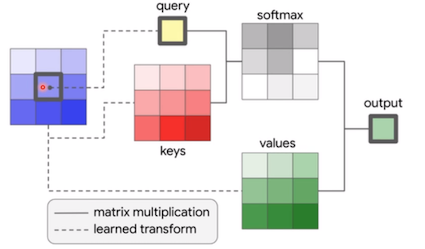
query 랑 key의 유사도를 계산하고 softmax를 취해 정규화 시키고, values를 합하여 output을 만듬
- kernel weights : query와 neighbor key들 사이의 유사도
Similarity
Dot-product attention
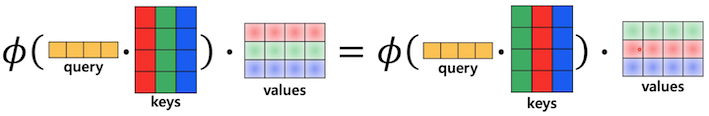
- Dot-product가 유사도로 사용
- self-attention은 key의 위치가 바뀌어도 invariant함
- pixel 값이 바뀔 수 있으므로 각 키에 positional encoding이 추가됨
generic formulation
위의 내용을 좀 더 일반화된 수직으로 아래와 같이 표현

Vector self-attention
유사도를 백터관점에서 볼 수 있으며 Point Transformer에서 사용함
- sim : vector subtraction + MLP
- softmax
dot-product 와 차이점은 dot-product 는 scaler지만 vector는 다른 백터들이 곱해져서 더 powerful하지만 메모리를 좀 더 많이 쓰게 됨
Point Transformer
relative position encoding을 더한 similarity에 MLP 통과 시키며, Value에도 relative position encoding을 더했을 때 실험적으로 더 좋은 결과로 나옴
Shape Classification, Part Segmentation, Semantic Segmentation에 SOTA를 달성함
- PointNet 은 locality가 없어 PointNet++을 설계하고 u-shaped net를 사용
- Point Transformer 은 좀 더 powerful한 knn을 이용한 local self-attention 을 사용해 SOTA 달성