AI 논문리뷰 - ACL/언어
Text Embedding for LLM
Main Research Questions
- 어떻게 다양한 길이/스타일/형태의 문서를 임베딩할까?
- 모든 형태의 문서를 단일 벡터로 만드는게 적절할까?
- 다국어 데이터나, 도메인 특화 데이터를 위한 임베딩은 어떻게 만들어야 할까?
Notable Researches : E5-mistral, BGE-M3
Text Embedding

2022 까지는 Encoding기반의 임베딩에서 Decoding 기반 임베딩들도 연구되고 있음
mteb leaderboard 참고!(전부 3개월 안에 나온 모델) -> Korea가 없음… Multilingual 를 활용해야하는데 임베딩에 대한 메모리 크기가 30GB 만큼 커서 작은 임베딩 연구가 계속되고 실용적임
E5 (2022) : EmbEddings from bidirEctional Encoder rEpresentations
BERT 기본 구조에서 성능을 크게 향상
기존 임베딩 모델들은 검색 성능이 부족
- 검색(얼마나 관련있느냐를봄)에 특화된 Pretrain
- Web에서 대량의 데이터 수집 후 약하게 학습(post-comment, title-passage 과 같이 Query + Passage를 모아서 약하게 학습 1~2 epoach)
- 모델로 데이터를 필터링하여 좋은 데이터 포집(CCPairs Dataset: 1.3B 가지고 약한 모델을 필터링 시켜 270M 데이터를 필터링)
인터넷의 수많은 저질 데이터를 필터링 시킨 데이터로 학습시켜도 충분히 좋다
CCPairs 로 InfoNCE Loss 학습
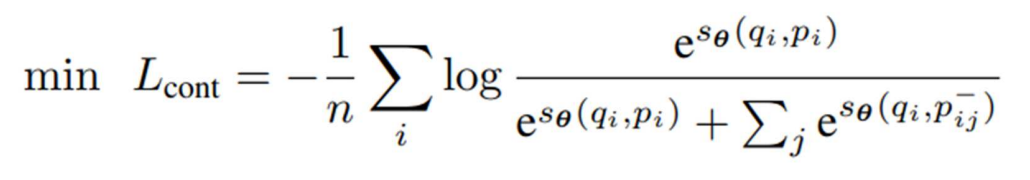
Positive 유사도 / (Positive 유사도 + Negative 유사도)
positive는 키우고 Negative는 줄이도록 학습
Hard Negative를 이용한 Fine Tuning
- Hard Negative : 정답은 아니지만 유사한 어려운 오답
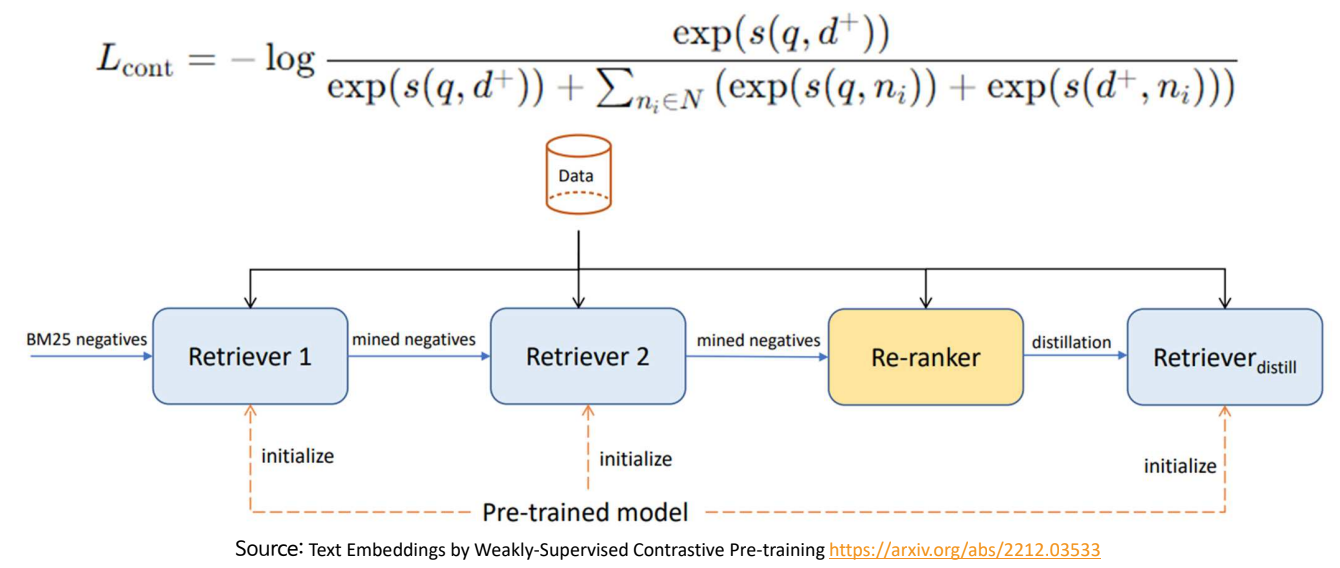
E5의 문제점: − 학습 과정이 복잡함 (3단계 Fine Tuning)
- Fine Tuning: 수작업으로 생성한 데이터에 의존
LLM Decoder의 성능을 Leverage하여 임베딩 생성 모듈로 활용하면 어떨까?
- MLLM의 Llava와 유사한 아이디어
- 너무 느리고 복잡해 디코더를 이용해 Leverage 하면 어떻까?
E5 -> E5-mistral : LLM을 임베딩 생성기로
GPT를 이용해 다양한 Task의 Pos/Neg Document Pair 생성
Improving Text Embeddings with Large Language Models (ACL 2024) 논문
LLM Backbone에 Query, Passage를 각각 입력
- 마지막 [EOS] 토큰의 벡터를 추출하여 임베딩 생성
- InfoNCE Loss를 이용하여 학습(LoRA r=8,32 사용)
gte embedding, llm2vec 모델들이 있음 -> LLM을 임베딩 생성기로 활용하겠다
디코딩은 마스킹을 하지만 이부분을 뚫어 마스킹을 없애는 방법 -> LLM2Vec
논문의 강점
- LLM의 풍부한 능력을 활용하는 SOTA 임베딩 대표 모델
개선점
- LLM 추론 속도와 동일한 임베딩 생성 속도: 실용성이 있을까?
BGE-M3: 다국어, 다기능, 다목적 임베딩
성능이 가장 좋고 가벼움
모든 형태의 문서를 단일 벡터로 만드는게 적절할까? 질문의 답
XLM-RoBERTa 기반의 Encoder 모델
- Dense Retrieval
- 텍스트 전체를 벡터로 임베딩하는 기존 방식
- Sparse Retrieval
- 단어별로 비교하여 유사도 기반으로 검색
- Multi-Vector Retrieval
- 단어를 Context를 고려한 벡터로 변환 상호작용을 계산하여 검색
XLM-RoBERTa를 Pretrain하는 것이 좀 어려움
Pretrain: RetroMAE (EMNLP 2022)
- MLM 방식은 문맥을 충분히 반영하지 못함
- Encoder/Decoder 구조에서 서로 다른 마스킹
- Encoder의 결과를 활용해 Decoder는 원문 복구
- “어려운 복원 작업으로 인코더 강하게 키우기”
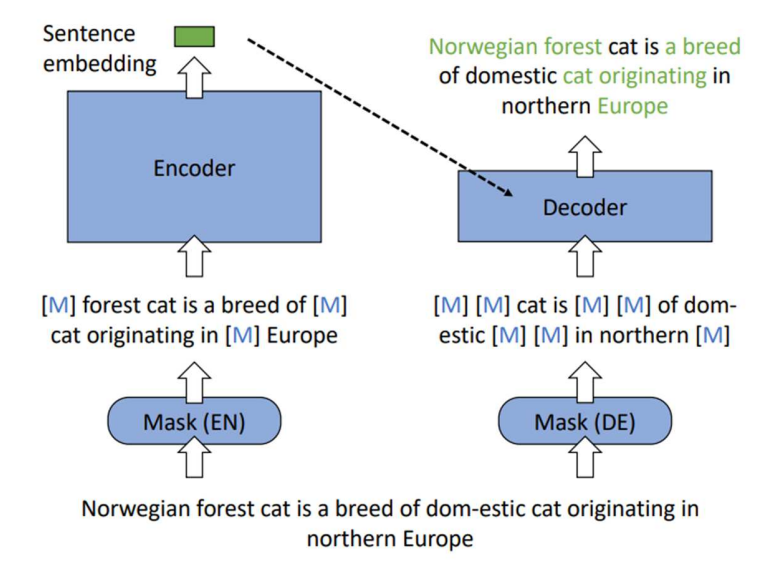
“RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder”


위의 3가지 Loss 가 계산됨
3가지 방식을 모두 하려니까 학습이 복잡함
3가지 학습 결과가 각자 다 다르니까 3가지 Metric으로 합친 점수를 가지고 각각의 Metric을 다시 공부 -> Self-Knowledge Distillation
앙상블 효과로 잘할 것이다.
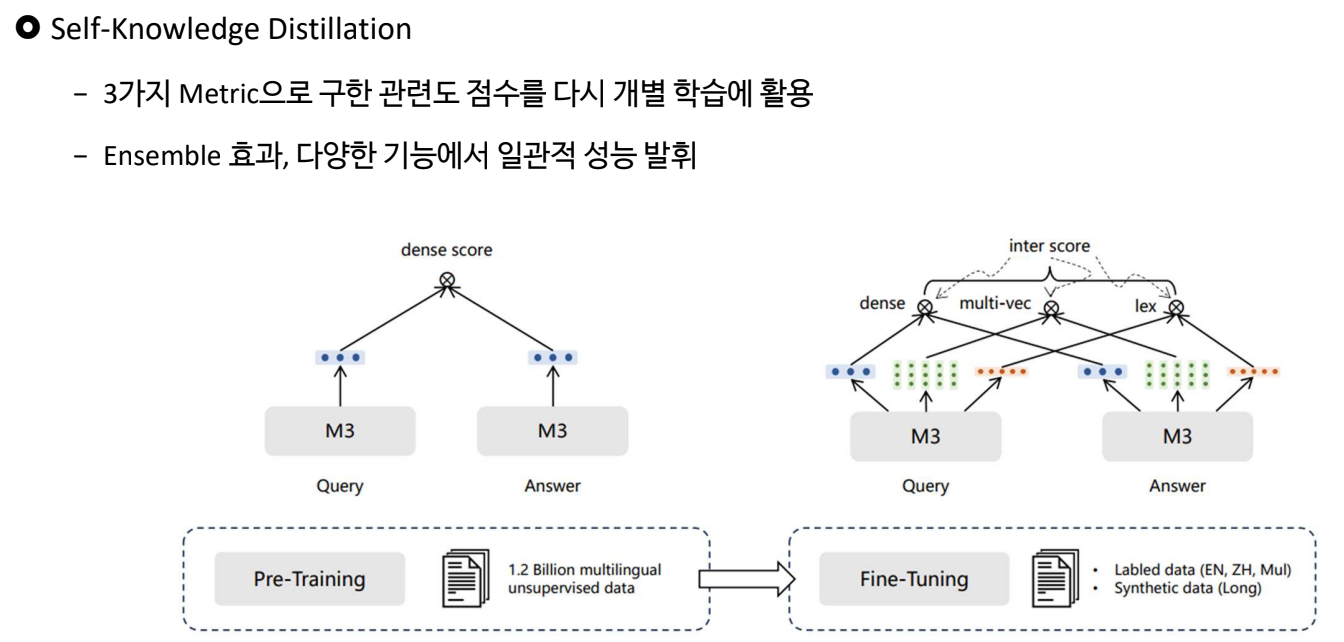
논문의 강점
- Non-LLM 형태의 대표 공개 임베딩 모델 (2G 정도의 크기)
- OpenAI Embedding-3-Large보다 뛰어난 성능
개선점
− 추후에 개발되고 있는 LLM 모델들 대비 성능 추월 가능 https://huggingface.co/spaces/mteb/leaderboard
M3와 Reranking을 붙이는 것이 현재 가장 성능이 좋음
최근 재밌는 논문들
COT로 답변하는데 25자로 줄여와 같이 restricted chain of thought 식으로 하는 것에 이어진 논문
현상 목격 결론을 순차대로 차례로 출력해~
Open AI 에서 Struectured Output을 내줌
이 논문은 Step by step으로 말하면서 json으로 출력하면 성능이 떨어질 수 있다를 제시함
why? 형식이 들어왔을 때 형식에 매몰되어 지식을 까먹는다