Machine Learning Problems

Clustering - 유사한 objects 끼리 grouping 시키는 프로세스
Clustering Algorithms

Hard vs Soft Clustering
Hard Clustering - 각각의 sample들은 하나의 cluster에 속함(0 or 1)
Soft Clustering - 확률적으로 계산(여러 cluster에 속할 수 있음)
K-means
각각의 클러스터 마다 ‘중심’이 하나 식 존재하고, 각각의 데이터가 그 중심과 ‘얼마나 가까운가’를 cost로 정의함
이 cost를 가장 줄이는 클러스터를 찾는 알고리즘 임
initial cluster centers에서 시작
Iterate:
- 각각의 example들에서 위의 center들 중 가까운 center의 클러스트로 assign 시킴
- 클러스터 안의 중심 pointers를 center로 다시 잡고, 재계산하여 위의 과정 반복
더이상 값이 변하지 않을 때 종료됨
Cosine Similarity
K-means 알고리즘에서 거리 계산할 때 cosine similarity를 이용

유클리드 거리 계산 법은 위와같은 문제 존재(q와 d2가 가장 유사한데 d2의 거리가 가장멈)
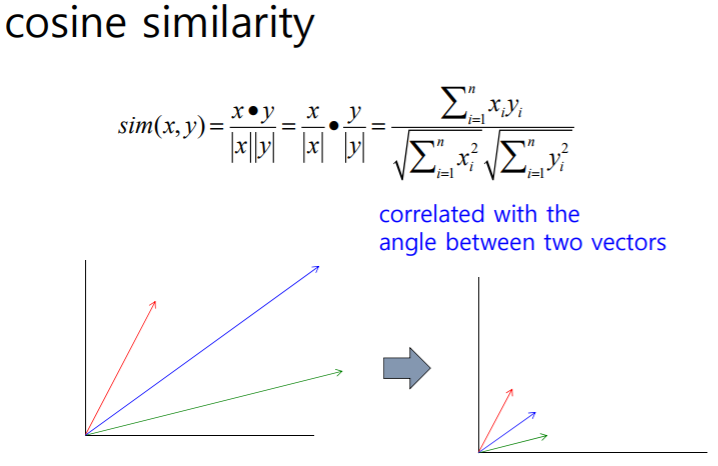
실제 거리는 유사도가 적을 수록 크고 유사도가 클수록 거리는 가까워야 하기 때매 1을 빼줌
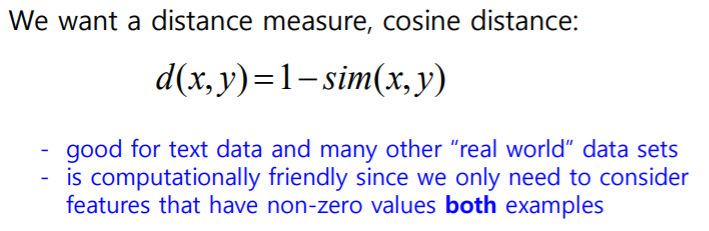
K-means Loss Function

각 cluster의 center 와 해당 cluster의 example들 간의 거리가 최소가 되는 center를 찾아감
How K-means Partitions?
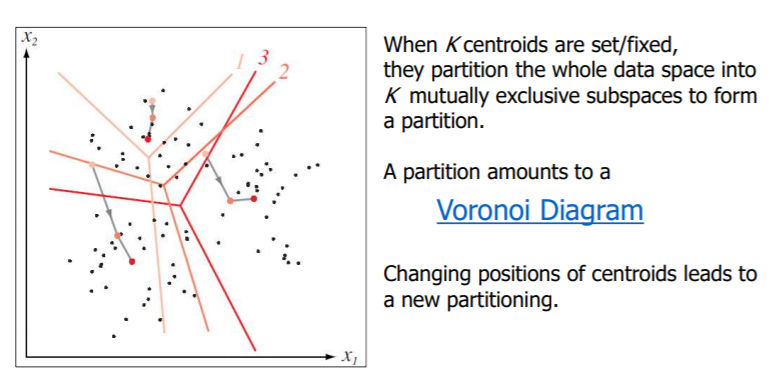
Voronoi Diagram
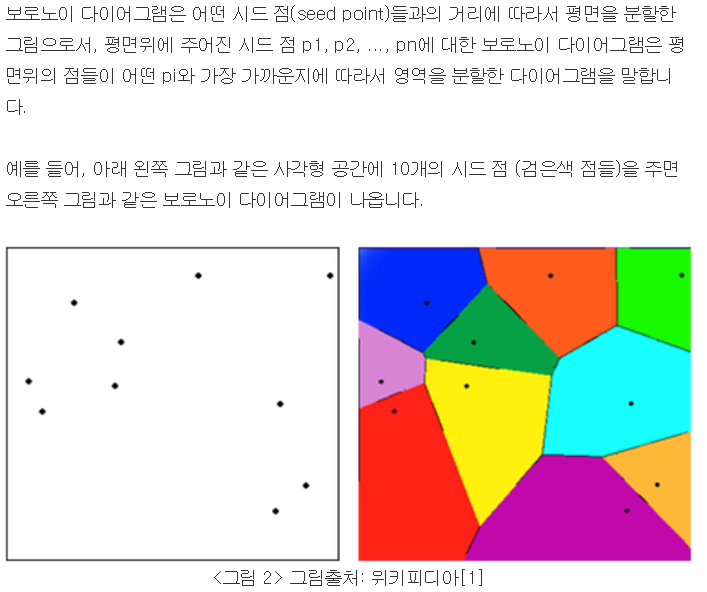
참고 : http://darkpgmr.tistory.com/96