Meta 연구원 문경식의 단일 이미지 인식을 통한 Human Pose Estimation 참고 정리
여러사람의 3D Pose Estimation
단일 사람 vs 여러 사람의 3D Pose Estimation
3D Pose Estimation
- 입력 이미지로 부터 사람 관절의 3D 좌표를 추정
- 입력 : 한 사람이 중심에 있는 이미지
- 출력 : 입력 사람의 root joint-relative 3D 관절 좌표
한 사람을 여러사람으로 확장
2D Multi-Person vs 3D Multi-Person Pose Estimation
Top-Down 방식으로 봄
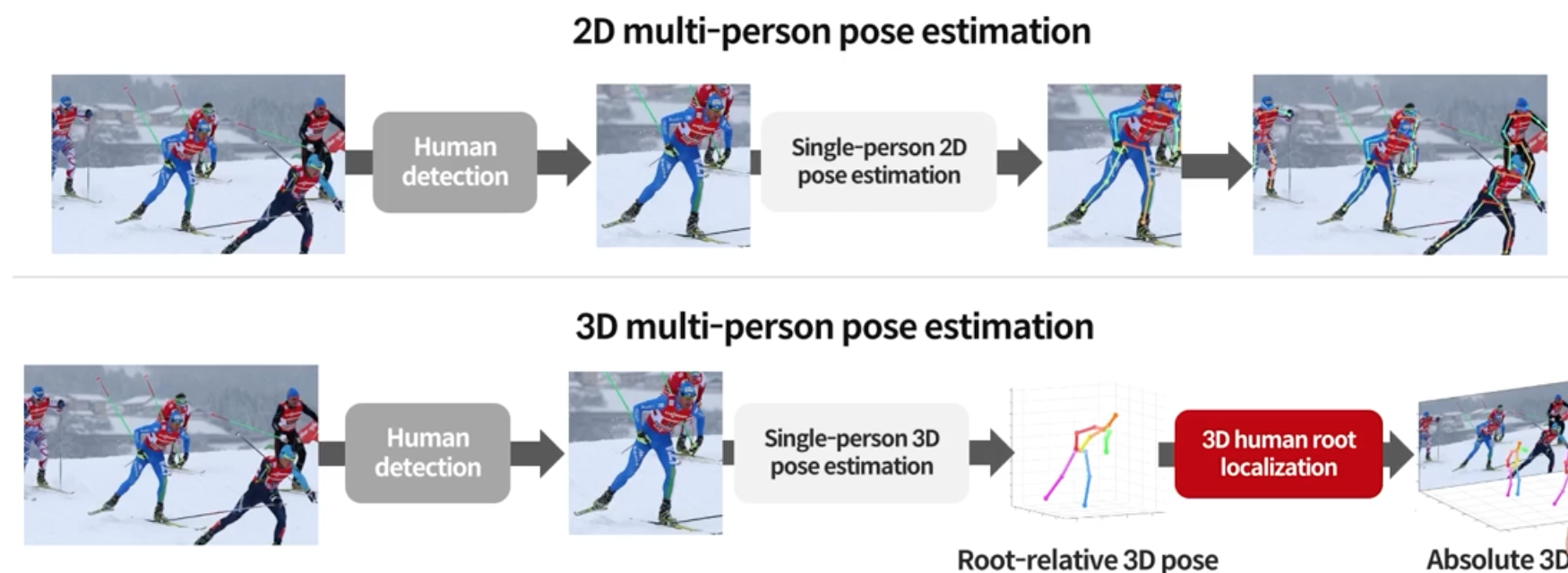
2D 와의 차이점은 z 까지 추정 해야하는 것이 어려움(카메라를 기준으로 3D Human root localization 을 해야함)
- 단일 사람을 위한 3D Pose Estimation 기법들은 모두 root joint-relative 3D Pose 를 추정
- 하지만 여러 사람의 3D Pose 를 위해서는 root joint-relative 3D Pose 가 아니라 absolute 3D Pose 가 필요
Bottom-up 접근법들은?
- 여전히 root joint-relative 3D Pose 를 추정
- 마찬가지로 absolute 3D Pose 를 위한 추가적인 모듈 필요
결국 root joint 를 위치화하는 모듈이 있어야함!
3DMPPE(2019)
각 사람마다의 3D Pose 뿐 아니라 여러 사람 사이의 상대적인 3D Pose 까지 찾는 것이 목표
기존 3DMPPE 방식
- Top-down: Human Detection + 3D SPPE(Lcr-net:Localization-classification-regression for human pose)
- Bottom-up: 3D Keypoint Detection + Grouping(Single-shot multi-person 3d pose estimation from monocular rgb)
위의 두 방식 모두 root joint-relative 3D Pose + root 위치를 얻으며 이 때 3D to 2D fitting 을 통해 얻음
3D-to-2D Fitting
추정된 2D Pose와 project 된 3D Pose 사이의 pixel 거리를 최소화
root joint 의 root 위치를 특정 점으로 설정 후 이미지 space 에 projection 시켜서 pixel distance 를 측정해 최소의 pixel 위치의 점을 찾음
한계점
- 2D Pose 와 3D Pose는 모두 추정된 값들이기 때문에 틀릴 수 있으며, 학습 기반의 알고리즘이 아니라 추정치에 매우 민감함
- 에너지 minimization 추정으로 노이즈에 민감함
3D MPPE
이 한계점을 3D MPPE 에서 처음으로 제안
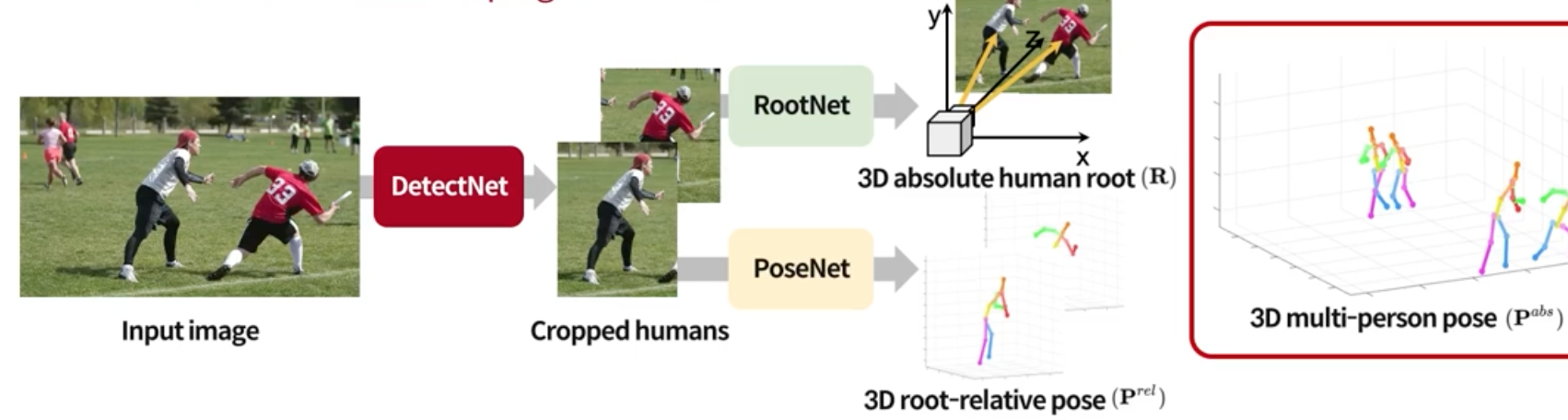
3D absolute human root 도 학습으로 이루어짐
3개의 분리된 네트워크로 나뉘어짐
DetectNet: Human Detection Network
- Pre-traind Mask이 사용됨
- 다른 네트워크도 사용 가능
PoseNet: Root-relative 3D SPPE
- 하나의 cropped human image를 입력
- 각 body joint 마다 3D Heatmap을 추정(x,y: image space, z: root joint-relative depth)
- Soft-argmax가 3D Heatmap으로 부터 좌표를 추출하기 위해 사용됨
- ResNet-50과 세개의 deconv + BN + ReLU upsamplers
RootNet: Root Joint Localization
- 하나의 cropped human image를 입력
- root joint 의 위치를 추정(x,y: image space, z: absolute depth)
- 단일 이미지로 부터 absolute depth 를 어떻게 추정?(카메라에서 보이는 사람이 얼마나 떨어져있는지 어떻게 알 수 있을까?, 줌을 몇 배 했는지?)
- 크기가 작고 카메라에 가까이 있는 물체 vs 크기가 크고 카메라에 멀리 있는 물체(Scale Ambiguity)
위의 문제를 풀기 위해 Camera Pinhole Model 을 가져옴
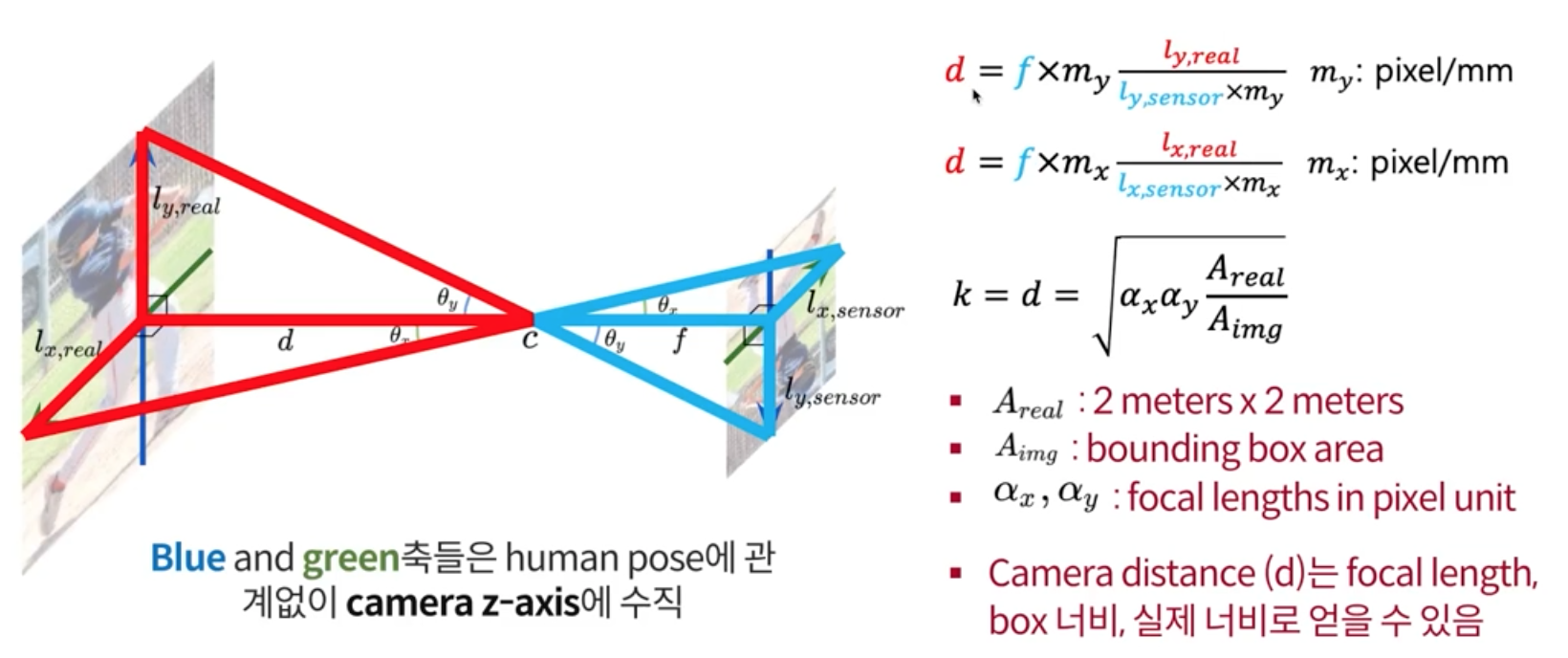
- 왼쪽 이미지가 실제 세계고 오른쪽이 카메라 렌즈에 비치는 사람이며, d가 궁금한 것 임
- Mocab데이터 셋에는 d 값($a_x, a_y, A_{real}, A_{img})$이 다 있으며, root joint depth와 의미 있는 상관관계를 가짐을 암
- 단, d 가 틀리는 경우가 있는데, 쭈구리고 있는 자세일 경우 $A_{img}$ 는 2D-Projected $A_{real}$ 보다 작음
- 또한 아이 같은 경우 뒤의 어른이랑 아기가 앞에 있을 경우 바운드 박스가 비슷할 수 있음
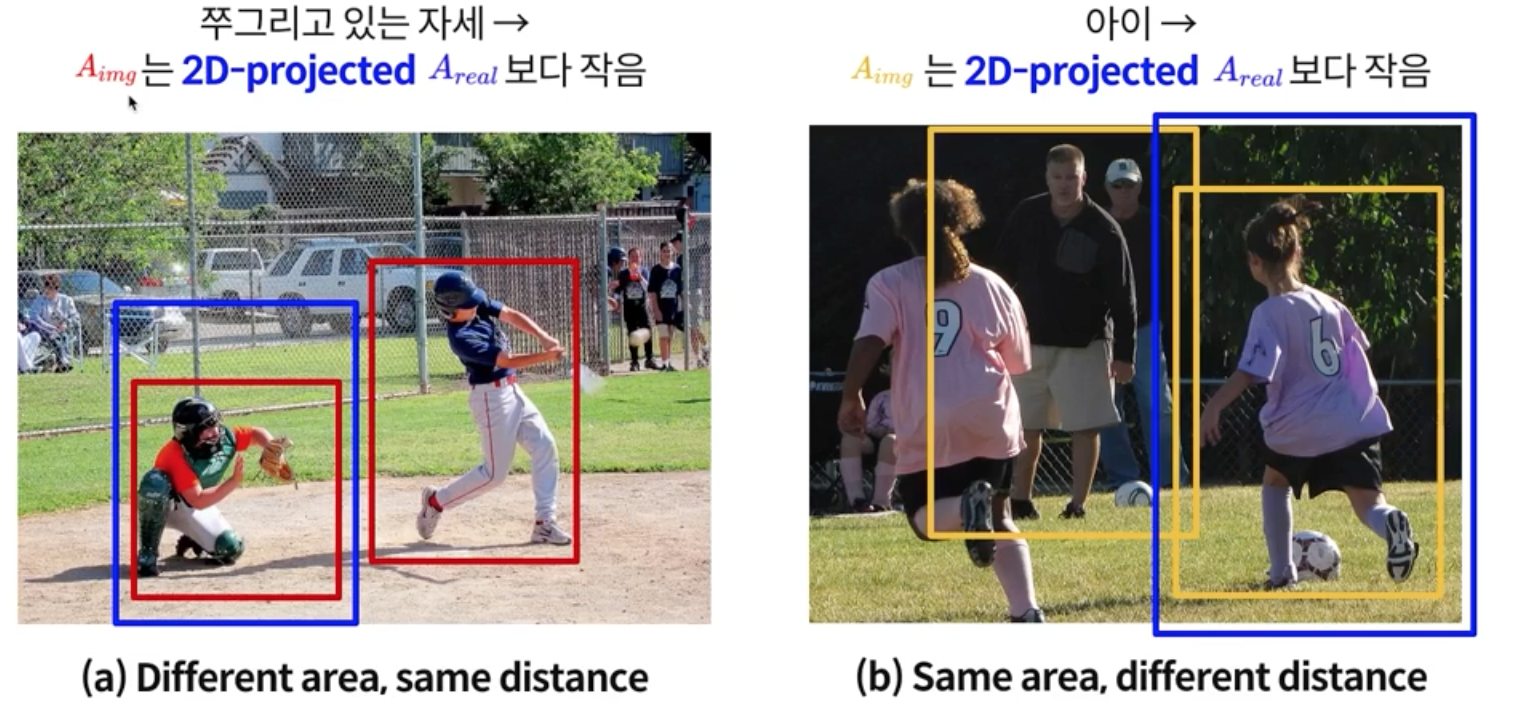
따라서 Pose랑 생김새로 인해 틀릴 수 있는 것을 RootNet을 통해 해결
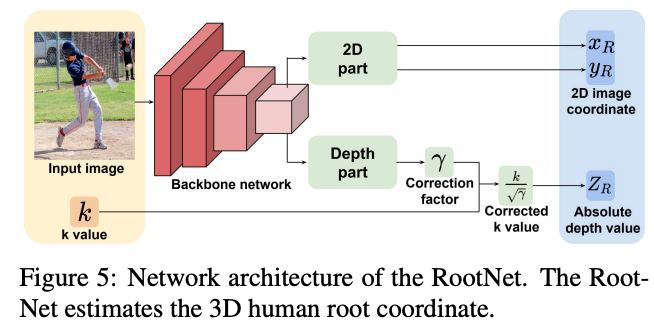
- Image Feature를 통해 human pose and appearance 정보를 갖고 있으며, Correction factor를 출력하고 initial depth value k에 곱함
3DMPPE(PoseNet)
https://github.com/mks0601/3DMPPE_POSENET_RELEASE
3DMPPE(RootNet)
https://github.com/mks0601/3DMPPE_ROOTNET_RELEASE