Meta 연구원 문경식의 단일 이미지 인식을 통한 Human Pose Estimation 참고 정리
Bottom-Up 모델

Joint Detector은 Top-Down과 별 차이 없으며 Grouping을 어떻게 할지가 모델 구성의 핵심
Associative Embedding(2017)
Associative Embedding 네트워크
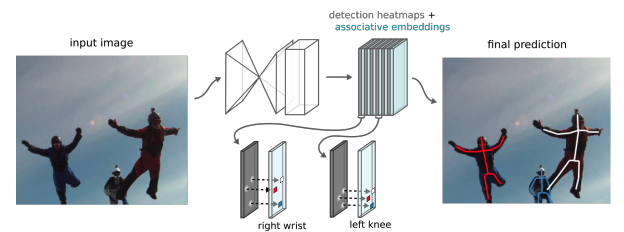
- 관절 탐지를 위해 2D heatmap 추정
- 탐지된 관절들을 사람별로 grouping하기 위해서 Associative Embedding을 도입
Associative Embedding 이란?

- 각 픽셀들의 “tag value”를 의미 (해당 픽셀이 어떤 사람에 속하는지 나타냄)
- 같은사람은 같은 tag value를 갖도록, 다른 사람은 다른 tag value를 갖도록 학습
- 테스트 단계에서 tag value의 차이가 미리 정해둔 임계값보다 작을 경우 두 관절은 같은 사람에 속한다고 판정
- 보이는 부분만 하기 때문에 남자의 팔꿈치가 가려져 여자의 팔꿈치 영역으로 잘못 판단할 수 있음
- 픽셀만 하고 채널이 없어 보이는 부분에만 집중해 에러가 존재할 수 있음
HigherHRNet(2020)
- Grouping말고 JointDetector을 개선한 논문
- Top-down 접근 법인 HRNet과 같은 motivation 공유(고해상도 feature map의 사용)
- 이미지에는 다양한 Scale을 가진 사람이 있음
- Multi-resolution supervision을 도입: 여러 resolution의 heatmap을 추정하도록 학습
- Multi-scale fusion을 도입: 여러 resolution의 heatmap을 조합하여 더 나은 추정을 하도록 학습
HigherHRNet 네트워크

- HRNet에 Multi-resolution supervision, Multi-scale fusion을 추가하여 다양한 Scale에서 포즈 추정한 Bottom-up 모델 디자인
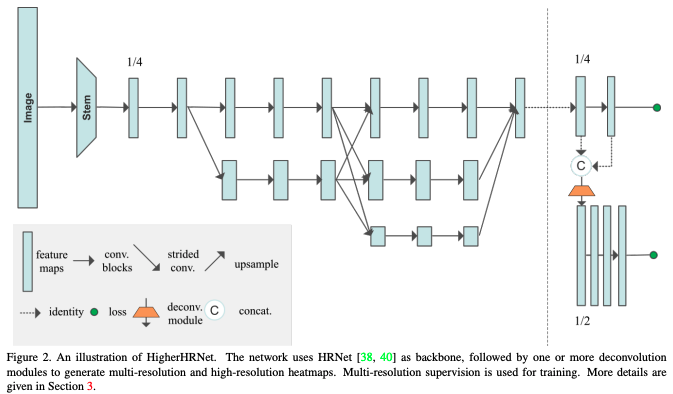
- grouping은 associative embedding을 사용
- HRNet기반의 network로 관절을 탐지하고, Associative Embedding을 사용해 탐지된 관절들을 group하여 여러 사람의 pose를 추정함