Meta 연구원 문경식의 단일 이미지 인식을 통한 Human Pose Estimation 참고 정리
2D Human Pose Estimation
입력 이미지로 부터, 사람의 관절을 2D 공간에 위치화 시키는 것
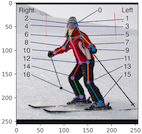
MSCOCODataset 예시: (‘Nose’, ‘L_Eye’, ‘R_Eye’ …)
Input Shape : H * W * 3
Output Shape : N * J * 2
N: 사람 명 수를 의미
J: 관절 개수를 의미. 고정된 상수이며 MSCOCO는 17
2D Human Pose Estimation의 도전적인 문제
- 사람끼리의 많은 가려짐
- 복잡한 자세
- 작은 해상도 -> 카메라에 가까운 사람들은 크고 정보가 많지만 먼 사람들은 작고 정보가 적음
- 모션블러(움직임에 따른 불안정한 해상도) -> 아이돌 춤과 같은 빠르게 움직이는 분야
- 잘림(상반신만 보여지는 이미지)
2D Human Pose Estimation 네트워크 학습
간단하게 한명의 사람의 Crop된 이미지가 있다고 가정
네트워크 구조 : Input Image -> Feature Extractor -> 2D Heatmap
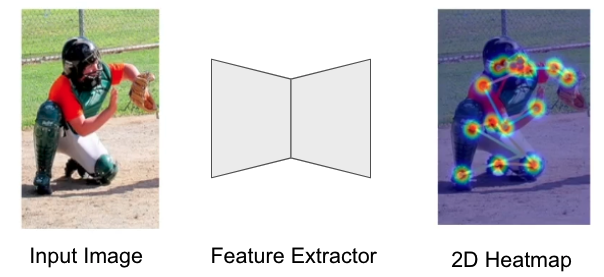
2D heatmap: J * H * W
j번째 2D heatmap 마다 하나의 Gaussian blob이 j번째 관절의 위치 중심에 만들어짐
예를들어 오른쪽 팔꿈치의 2D heatmap 은 나머지는 0이고 오른쪽 팔꿈치 근처에만 2D Gaussian blob이 있음(관절마다 각각 Gaussian blob이 있음, 즉 관절마다 2D heatmap이 있다고 이해하면됨)
네트워크 구조 : Input Image -> Feature Extractor -> 2D Joint coordinates(‘Nose’:(127,200), ‘L_Eye’(100,200) … )
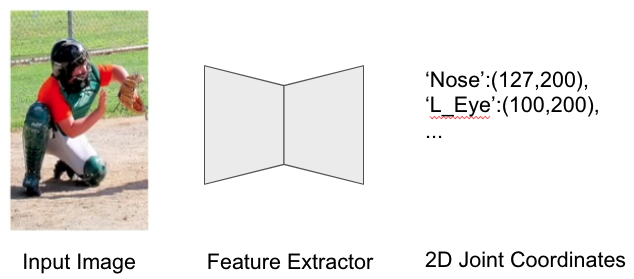
2D 좌표를 직접적으로 추정하는 네트워크도 있지만 직접 추정 시 매우 비 선형적인 연산을 요구
-> Feature Extractor 좌표 이미지의 경위 높이, 너비 개념이 보존이 되지만 좌표를 추정하기 위해 Feature 를 Vector 화 해서 입력 이미지의 높이, 너비 개념이 없어서 매우 비선형적 연산을 요구해서 실험적으로 성능이 낮다는 것이 알려짐
-> 반면 2D Heatmap 의 경우 연속적인 Convolution만으로 추정 가능해서 높이와 너비에 대한 특징이 유지되어 직접 추정하는 것 보다 Heatmap이 높은 성능을 달성한다
-> 단 좌표를 직접 추정하는 것이 dimension이 낮지만 정확도 차이가 꽤 나서 Heatmap 방식이 일반적임
네트워크 학습 구조
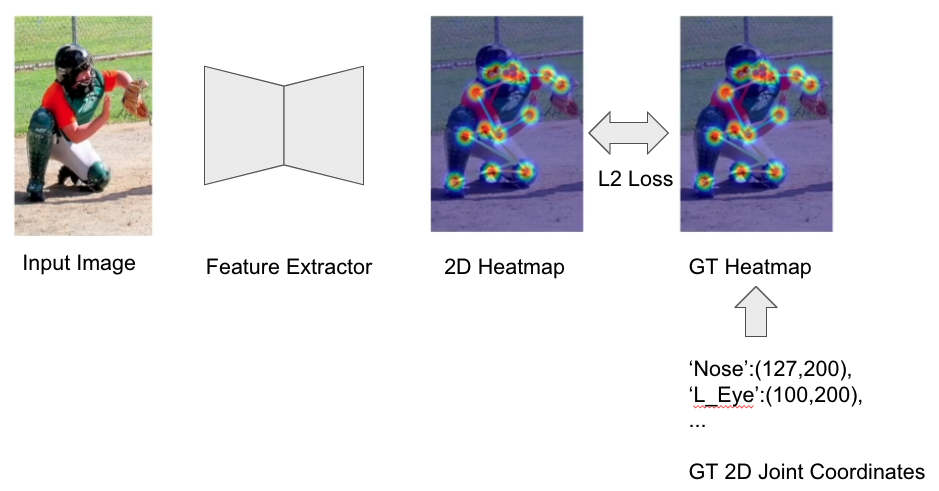
가장 간단한 학습 파이프라인
추정된 2D Heatmap 과 GT 2D Heatmap 사이의 L2 Loss(실제값과 예측치 차이의 제곱의 합) 최소화
- 관절이 입력 이미지에서 정의가 안되어 있을 경우?
- 사람이 많아 자려지거나 상반신 이미지의 잘림 같은 경우 loss를 0으로 보통 설정
j번째 2D Heatmap에 2D argmax를 적용해 (X, Y) 좌표를 얻을 수 있음(마지막에 confidence도 추가 가능)
Top-Down 접근법 vs Bottom-up 접근법
이제는 Multi-Person Pose Estimation으로 확장해서 봄
Multi Person 자세추정에는 Top-Down과 Bottom-up 접근법이 있음
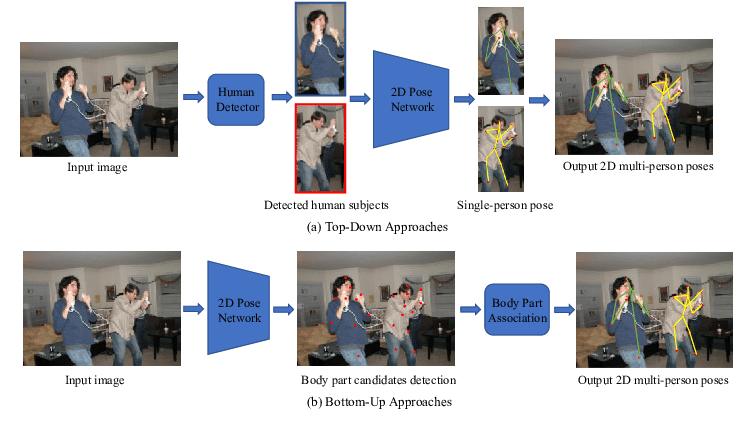
이미지 출처: Deep Learnign-Based Human Pose Estimation: A Survey by Ce Zheng
Top-Down 접근: Human Detection + Single Person Pose Estimation
- Bottom-up 접근들 보다 뛰어난 정확성(MSCOCO 기준 AP 78이고 bottom up은 71 정도임)
- 단점 : Human Detection이 실패하면 Pose를 추정할 수 없음
- 최근 발표되고 있는 yolov5, yolov7 등 Human Detection 네트워크가 발전하고 있음
- Human Pose Estimation에 쓰이는 사람 입력 이미지가 고해상도(카메라에서 가까운사람은 크고 먼 사람은 작지만 먼 사람도 crop 후 큰사람과 똑같은 scale로 리사이즈함)
- 단 하나의 네트워크가 아닌 두 개의 분리된 네트워크로 Bottom-up 보다는 Cost가 큼
- Bottleneck은 Human Detection이 아니라 Pose Estimation에 있어 Detection 성능에 따라 전체 속도 성능 증가는 미미함
Bottom-up 접근: Joint Detection + Grouping
어떤 사람에 속하는지 상관하지 않고 모든 팔꿈치 Joint를 찾은 후 Grouping
- Top-down 접근들 보다 낮은 정확성
- Human Pose Estimation에 쓰이는 사람은 입력 이미지가 저해상도 일 수 있음(먼사람의 작은 정보의 이미지가 Input으로 들어감)
- 여러 Scale을 고려해야하는 어려움이 존재(Top-down은 Detection후 하나의 Scale로 리사이즈함)
- 하지만 한 네트워크가 연산하기 때문에 Cost는 효율적