ACID 의 Atomicity, Consistency, Durability
Failure Classification
Transaction failure
- logical errors 에 의해 transactino 자체가 error 발생
- system errors: dbms 가 deadlock 같은 error로 인해 종료되는 현상
System failure(crash)
- 메모리의 내용이 없어지는 현상
- 전원이 종료되거나 하드왜어로 인한 crash
Disk failure
- head 가 crash 난다거나 하드디스크가 오래되었다던가..
- 하드디스크 내용 중간에 분실될 경우
기본적으로 DBMS가 지원하는 Recovery는 이 3가지 failure를 지원을 위한 여러가지 알고리즘이 구현되어 있음
Recovery Algorithms
database의 consistency을 보장하고 transaction의 atomicity 와 durability를 보장하는 기술(failures 임에도 불구하고)
- transaction이 정상적일 때 어떤 action을 취하고 있는지 고려해야함
- 시스템이 failure가 나면 recover 를 하기위해 어떤 action을 취하고 있는지 알아야함
평상시에 DBMS가 Recovery를 위해 어떤 일을 하는지와 실패했을 때 어떤 일을 하는지 분리해서 분석해야함
Data Access
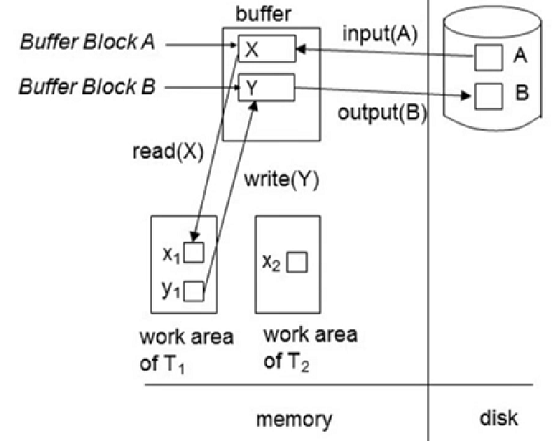
기본적으로 data는 모두 disk에 있음
memory에 올리기 전에 data가 system buffer로 올라오는 연산을 input, buffer 가 disk로 다시 내려가는 연산을 output 이라함
system buffer 에 있는 것을 어떤 Transaction의 local area로 가져와 read, write 하는 것임
dbms 사용자 관점에서 read, write는 바로 buffer 에 하지만 buffer 에서 disk로 input, output 하는 것은 buffer manager 가 관리하고 있음(실질적으로 disk에 내려가지 않은 경우도 많음)
시스템 crash가 나면 memory 데이터가 날아가므로 disk에 반영되지 않을 수 있다는 점도 고려해야함
Recovery approach
Two approaches
1.log-based recovery
아래 자세히 설명
2.shadow-paging
- text editors에서 많이 사용
- 요새는 dbms에서 안쓰고 간단한 text editors에서만 사용
- 원래 copy에서 복사본을 만든 후 업데이트함, 업데이트가 잘 끝나면 원래 copy를 삭제하는 방식임
- copy하는 연산이 너무 복잡하고 비싸 잘 사용안함
stable storage에 log를 쓰는데 로그는 변경된 내역(값을 어떻게 고쳤다)을 적는 것임(로그가 없어지는 경우는 고려하지 않겠다는 것)
기본 원칙 중 하나가 stable storage 에 log를 먼저 쓰고 disk를 고쳐야함(WAL - write ahead logging)
Log-Based Recovery
log 는 stable storage에 보관
log는 log records의 sequence로 어떤 database 연산이 일어났는지 알 수 있음
log records 타입
- <Ti, start> - Ti가 시작
- <Ti, X, V1, V2> - Ti가 X를 V1(undo를 위해)에서 V2(redo를 위해)로 변경
- <Ti, commit> - Ti가 잘 끝났다
Multiple transaction이 concurrently하게 running 할 것임
모든 transaction은 a single disk buffer와 a single log를 사용
Checkpoint
recovery 하는 시간을 단축하기 위해서 DBMS가 주기적으로 checkpoints라는 작업을 함
main memory에 있는 모든 내용을 disk에 write 함
지금까지 한 모든 DB연산이 모두 반영되니까 recovery를 했을 때 checkpoints 이후만 살펴보면됨
recovery 시간 단축을 위해 존재
checkpoint L -> L: active한 transactions list
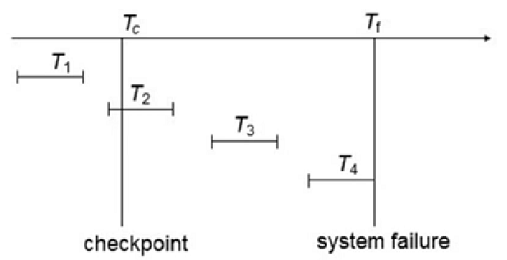
- T1은 고려안해도됨 - T1의 디스크에 다 반영됨
- T2, T3는 database에 반영되야하지만 disk에 내려가는 것은 buffer에 의해 내려가므로 필요하다면 redone해주어야함
- T4는 undone 해주어야함
Recovery
When the system recovers from a crash
- undo-list, redo-list 초기화
- log 를 뒤에서 부터 Scan 하여 첫번째
record 가지 찾음 - record가
이면 Ti를 redo-list 에 넣음 - record가
이고 Ti가 redo-list 에 없으면 undo-list 에 넣음 - L에 있는 모든 Ti에 대해 redo에 없으면 undo에 넣으면됨
- 다시 뒤에서 부터 scan하여 undo-list 를 undo
- 가장 최근 꺼의 checkpoint L을 찾음
- L에서 시작해서 forward로 scan하여 redo-list 를 redo
Log Block Buffering
Log records도 main memory에 buffered 됨
log force operation이 실행되면 지금까지의 모든 log record가 stable storage에 output 됨
transaction이 commit 되면 Log force를 수행함(commit 할 때 수행하는 것 중 하나가 Log force 임)
commit 할 때마다 disk write를 무조건 해야하는 것임
시스템에서 Group commit 이라는 일을 함 - disk write 시간걸리니까 several log records가 full이 될 때 까지 기달렸다가 한번에 진행해서 I/O cost 를 줄임(다수개의 transaction이 commit 하고 있지 않다가 일정 로그가 싸이면 다수 transaction이 한번에 commit 을 진행하여 group commit 이라함)
log record가 data block이 disk output 에 먼저 쓰기 전에 stable storage 에 output 되어야함(WAL)
log 없이 system crash가 났을 때 어떻게 변경됬는지 몰라 recovery할 수 없음
Deferred Database Modification
log record 만 만들고 실제 write 하지 않고 transaction이 commit 될 때 write 함(지연된 변경)
crash가 일어나 recovery를 수행할 때 commit 이 있으면 redo하고 없으면 무시함
따라서 log를 쓸 때도 <Ti, X, V2> 만 사용해 공간을 줄일 수 있음
Immediate Database Modification
buffer blocks이 commit 과 상관 없이 output 연산이 수행 될 수 있음
log record는 반드시 data가 write 전에 쓰여지도록 보장해야함
crash가 일어나 recovery를 수행할 때 commit 이 있으면 redo, 없으면 undo 수행