Meta 연구원 문경식의 단일 이미지 인식을 통한 Human Pose Estimation 참고 정리
Mask R-CNN(2016)
Mask R-CNN with KeyPoints 네트워크
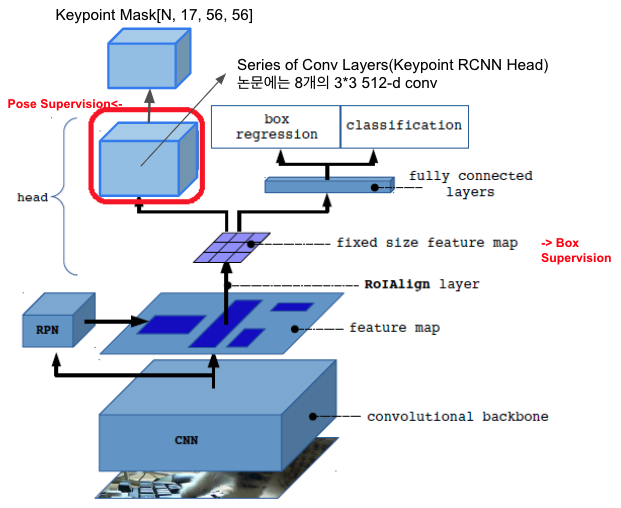
- 기존 방법들은 입력 이미지에서 사람 영역을 자르고 사이즈 조정함
- ROIAlign 은 입력 이미지가 아니라 feature map에서 자르고 사이즈 조정함
- Human Detection과 Pose Estimation 네트워크가 공유해 e2e 학습으로 효율적임
ROIAlign
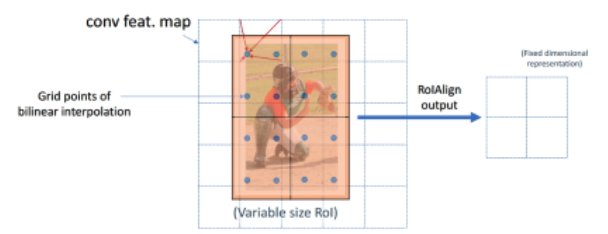
사람의 Boundbox로 추측된 ROI가 주황색깔 박스와 깉이 예측했다고 가정함
그 뒤에는 Conv Feature MAP의 픽셀들임
앉아 있는 사람의 4 * 4 Feature Map을 얻고 싶다할 때 뒤의 Conv Feature Map의 4 꼭지 픽셀 값을 통해 4가지 화살표로 향하는 파란색 점의 4 * 4 Feature Map 을 얻는 것임
이 때 bilinear interpolation이 활용됨
추출된 단일 사람의 feature를 pose estimation에서 사용됨
이 feature 로 부터 2D Heatmap을 추정(J * H * W)
기존 ROIPooling의 discretization 문제를 해결(ROIPooling은 Feature Map의 가장 가까운 값을 파란색 꼭지점의 픽셀 값을 씀)
ROIAlign은 ROIPooling에 비해 AP가 5정도 증가함
SimpleBaseline(2018)
SimpleBaseline 네트워크
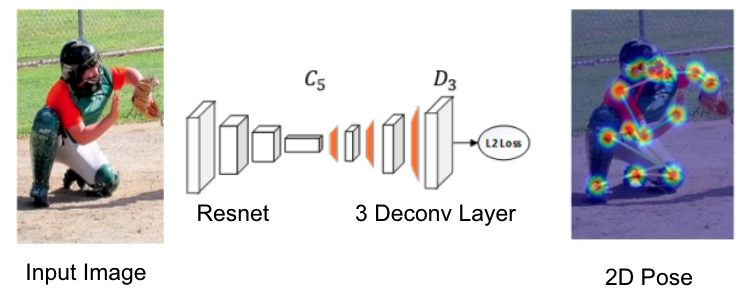
- 단순한 네트워크로 높은 정확도
- ResNet과 3개의 deconvolutional layer의 조합
- 단순하기 때문에 많이 쓰는 모델 중 하나
- OHKM(학습중간에 어려운 케이스의 LOSS를 크게주어 학습 시키는 테크닉)을 사용하지 않고도 높은 AP 달성
HRNet(2019)
HRNet 네트워크
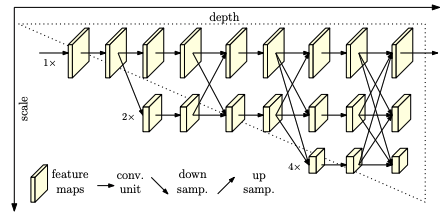
- 기존 Human Pose Estimation을 위한 backbones(eg ResNet) 들은 입력 이미지를 32배 downsampling 시킴
- 32배의 downsampling은 저해상도 feature map을 초래((보통 256256 이미지가 88 feature map으로 됨)
- 이런 저해상도는 손목과 같은 작은 파트는 없어져 Discretization 문제가 생김
- 위의 문제를 해결하기 위해 고해상도의 feature map을 효율적으로 보존
- Multi-scale feature fusing이 더 Robust한 feature 추출
- 1x 32개 채널, 2x 8배 줄어든 대신 채널을 64개로 늘려 각각 정보를 보충해 여러 Scale 정보를 같이 써 높은 성능을 얻음
- GFLOP 이 낮은데도 성능이 높아 효율적
- 그러나 SimpleBaseline이 GFLOP이 높지만 시간 성능이 더 빠름